
I had a great first Sugru experience! I scratched my finger on the way to work on my unicycle. I thought, dammit, I’m gonna fix that! So I bought some from my phone on the train. Cool!
A few days later, it arrived in the post. I was having a hard time explaining why I was so excited about it to my wife. So I sat down, cut open my first packet and started fixing. My wife got interested, fast! She asked, would this stick to the door handle to make a bumper? I said, go try! And off she ran with my Sugru, leaving me grinning and cutting open a new packet…
Thanks, Sugru, for our new door bumper and unicycle seat bolt covers! You made two new happy fixers.
Correction: Three new fixers, including Elio, age 2 and a half:
<iframe allowfullscreen="allowfullscreen" frameborder="0" height="480" src="http://www.youtube.com/embed/oGW0qZUuowA?rel=0" width="640"></iframe>

Here’s two stories that worked their charm on a not-very-sleepy little boy, turning him into a sleepy one.
Bep and the Giant Pumpkin: It is October, the official start of pumpkin season in our house. That means it is time to start talking about pumpkins and where we get them. So mommy, daddy, Elio and Emma got in Bep and went for a drive. They drove up up up to the top of Lausanne and then up up up to Mont sur Lausanne, then up up up more to the little self-service vegetable stand above it. Everyone went in and chose their pumpkins one by one. Emma got a little pumpkin because she needed to hold it between her feet in her maxi-cosi. Elio got a bigger pumpkin because he’s strong (Elio e forte!). Mami chose a good pumpkin for soup because she makes the best pumpkin soup. And daddy chose one to make a yummy pumpkin curry. Daddy was about to pay and go, but Elio asked, “What about Bep?” So they looked but none of the pumpkins were big enough for Bep. They went out back and found a perfect pumpkin, 1 meter across, 3.14 meters around and weighing 200 kg! They went to get Bep and asked, “can you carry it?” Bep said “beep beep vroom vroom, no problem” and drove the whole family home, each with their pumpkin on their lap (except mami, who was driving) and Bep with his pumpkin right in the middle.
The Little Red Robot: Once upon a time, there was a little red robot. (Elio was wearing his red robot pj’s.) This little red robot could do everything the master programmer taught him. He could dress himself, go poo poo, feed himself, read books, etc etc. He even knew how to initiate the food processing unit decontamination procedure (teeth brushing) and the light delumination protocol (turning off the bathroom light by head butting it). But each night, when the little red robot went into sleep mode, something magical happened. He got to do things he never did in the day. He ran programs for flying on clouds, climbing in trees, (around this point Elio interrupted and asked that the story should include a “motoschlitta”: snowmobile), and ride lunar snowmobiles across the moon through craters and over the horizon, far from the robot base. That night, the little red robot ran the snow mobile program in his processing unit all night. In the morning when he woke up, he went to Central Dispatch and found that his job that day was to go drive lunar snowmobiles for real! And so he did.
Here’s the setup I use for compiling Go binaries, as well as for writing .deb’s to package them and markdown for README’s – notes for me.
Install build pre-requisites:
sudo aptitude install gcc libc6-dev libc6-dev-i386 make \ markdown build-essential debhelper dh-make fakeroot devscripts
Install Go from source (so can cross-compile). Download from Go Downloads eg go1.0.2.src.tar.gz
sudo tar -C /usr/local -xzf go1.0.2.src.tar.gz ; cd /usr/local/go/src sudo GOARCH=amd64 ./all.bash ; sudo GOARCH=386 ./all.bash
Add to /etc/profile, source or re-login:
export GOROOT="/usr/local/go" export PATH="$GOROOT/bin:$PATH"
[Edited: after some feedback, I have renamed this project to rjson (it's really not at all Go-specific) and changed the specification so that unquoted strings are accepted only as object keys]
JSON is a fine encoding. It has a very simple data model; it’s easy to understand and to write parsers for. But personally, I find it a bit awkward to read and to edit. All those quotes add noise, and I’m always forgetting to remove the final comma at the end of an array or an object. I’m not the only one either. I’ve chatted to people about why they are using YAML, and the reason is usually not because of the zillion features that YAML offers, but because the format is more human-friendly to edit.
A while ago I had an idea of how I might help this, and yesterday I had a free day to do it. I forked the Go json package to make rjson. It uses an idea taken from the Go syntax rules to make commas optional, and quotes become optional around object keys that look like identifiers. The rjson syntax rules are summarised in the rjson package documentation.
To make it easy to experiment with and use this format, I created a rjson command that can read and write both formats.
Here is a transcript showing how the command can be used:
% cat config.json
{
"ui" : {
"global" : {
"ui-type" : "default",
"show-indicator" : true
}
}
}% rjson < config.json
{
ui: {
global: {
show-indicator: true
ui-type: "default"
}
}
}
% rjson -indent '' < config.json
{ui:{global:{show-indicator:true,ui-type:"default"}}}
% rjson -indent '' -j < config.json
{"ui":{"global":{"show-indicator":true,"ui-type":"default"}}}
%
You might notice that the compact version of the rjson format is smaller than the equivalent JSON. On a random selection of JSON files (all that I could find in my home directory), I measured that they were about 7% smaller on average when encoded with gson -indent ”. This was a nice bonus that I had not considered.
To use rjson, you’ll need a working Go installation; then you can fetch and install the command into your go tree thus:
go get launchpad.net/rjson/cmd/rjson
Enjoy!

I've resurrected an idea I had awhile back regarding a simplified development environment. I've gotten tired of Eclipse and large IDEs over the years. The obvious benefit is that it can be built to suit my needs. Here is a picture of the first display prototype:  In the above prototype, the editor is in very much like a traditional editor. This isn't what I want, but I think it is important to meet common expectations. What follows is a screenshot of my current development effort. I think, there is enough novelty in this new vision to warrant continuing the development effort.  |


Here I am compiling a list of resources used to prepare for technical interviews: developer auction CareerCup TopCoder |
In a previous post I discussed mux()ing, which is probably one of my favorite things.
Here I will show a fun application of mux()ing that I’m calling a LimitBuffer. It’s similar to a bytes.Buffer, except that it limits the amount of data stored in its buffer at any given time. Calls to .Write() will block until they no longer overflow the buffer. Calls to .Read() will block until there is data to read or the LimitBuffer has been closed.
First, the basic type and constructor.
type LimitBuffer struct {
limit int
buf bytes.Buffer
writes chan writeRequest
reads chan readRequest
isclosed bool
}
func NewLimitBuffer(limit int) (lb *LimitBuffer) {
lb = &LimitBuffer{
limit: limit,
writes: make(chan writeRequest),
reads: make(chan readRequest),
}
go lb.mux()
return
}
Since we’re using a mux(), we need to create the channels that bring data safely into the mux() goroutine. The .writes channel will take care of calls to .Write() and .Close(), and the .reads channel will take care of calls to .Read(). Of these three important methods, .Write() and .Read() both have return values. Since channels are mostly one-way means of communication, we’ll have to do something extra here.
This brings us to the request and response types.
type writeRequest struct {
buf []byte
closeit bool
response chan writeResponse
}
type writeResponse struct {
n int
err error
}
type readRequest struct {
buf []byte
response chan readResponse
}
type readResponse struct {
n int
err error
}
The extra bit is the response channel in both request types. Since it takes a channel to get data in, it makes sense that we’d use a channel to get data out as well.
Both reading and writing have their own response types that wrap the return values of a normal .Read() and .Write() method.
Let’s look at the simpler operation first: .Read().
func (lb *LimitBuffer) Read(buf []byte) (n int, err error) {
req := readRequest{
buf: buf,
response: make(chan readResponse, 1),
}
lb.reads <- req
response := <-req.response
n, err = response.n, response.err
return
}
We created a request, loaded it up with the buffer and made a channel that the response could be sent back on. The channel is buffered so that the mux() wastes no time on unneeded synchronization when sending the data back. There’s no reason for it to wait around until the .Read()ing goroutine wakes back up and gets the response. Since the channel is buffered, it can drop the value in and go on its way with other operations.
I’ve made .Write() a little more complicated so that it will block until it is able to completely write the buffer into the LimitBuffer. Since the LimitBuffer will store only a certain amount of data at a time, this could cause .Write() to wait until more .Read() calls have been executed.
It would be acceptable for me to have let .Write() do partial writes, and return how much data was written, but then to be useful almost anyone would have to write a for loop similar to the one below.
If there were a .Write() analog to io.ReadFull(), I could use that here. But there isn’t, so I don’t. It would look a lot like this anyway.
func (lb *LimitBuffer) Write(buf []byte) (n int, err error) {
for len(buf) > 0 {
req := writeRequest{
buf: buf,
response: make(chan writeResponse, 1),
}
lb.writes <- req
response := <-req.response
m, werr := response.n, response.err
n += m
if werr != nil {
err = werr
return
}
buf = buf[m:]
}
return
}
Since in go-land closing is usually considered a write operation (at least, it is with channels), I have piggybacked on the write request to allow closing, too. Since I have decided that there is no possibility of error when closing, the writeRequest has no response channel.
func (lb *LimitBuffer) Close() error {
req := writeRequest{
closeit: true,
}
lb.writes <- req
return nil
}
Now we get to the meat of the code - the mux() method. Usually I like to have a single for{} with a single select{} inside, but in this case there are some special situations.
func (lb *LimitBuffer) mux() {
for {
If the buffer is closed, all .Write()s return an error, and all .Read()s return an error once the buffer has emptied.
if lb.isclosed {
if lb.buf.Len() == 0 {
select {
case req := <-lb.reads:
req.response <- readResponse{
n: 0,
err: io.EOF,
}
case req := <-lb.writes:
lb.handleWriteClosed(req)
}
} else {
select {
case req := <-lb.reads:
lb.handleRead(req)
case req := <-lb.writes:
lb.handleWriteClosed(req)
}
}
continue
}
If the buffer is at its limit, we’ll save the .Write()s for later.
if lb.buf.Len() > lb.limit {
lb.handleRead(<-lb.reads)
continue
}
If the buffer is currently empty, we can’t deal with a .Read() (or at least, I don’t want to).
if lb.buf.Len() == 0 {
lb.handleWrite(<-lb.writes)
continue
}
If it’s not closed, empty, or at its limit, then both .Read()s and .Write()s can happen.
select {
case req := <-lb.reads:
lb.handleRead(req)
case req := <-lb.writes:
lb.handleWrite(req)
}
}
}
Since some code would have been duplicated otherwise, I dropped it into helper methods.
func (lb *LimitBuffer) handleRead(req readRequest) {
n, err := lb.buf.Read(req.buf)
req.response <- readResponse{n, err}
}
func (lb *LimitBuffer) handleWrite(req writeRequest) {
if req.closeit {
lb.isclosed = true
} else {
m := lb.limit - lb.buf.Len()
if m > len(req.buf) {
m = len(req.buf)
}
n, err := lb.buf.Write(req.buf[:m])
req.response <- writeResponse{n, err}
}
}
func (lb *LimitBuffer) handleWriteClosed(req writeRequest) {
req.response <- writeResponse{
n: 0,
err: errors.New("Writing to closed stream"),
}
}
Here is a gist with the full code embedded in an example program.
Why I am keeping this information is a mystery. func main() { var i uint32 = 0x12345678; x := (*[4]byte)(unsafe.Pointer(&i)) for _, xn := range *x { fmt.Printf("%x\n", xn) } } |
At one point, in the #golang IRC channel, I had occasion to explain why you cannot define a method on an interface type.
Here is the code whose behavior you can mull over.
package main
type Concrete int
func (c Concrete) Foo() {
println("concrete foo")
}
func (c Concrete) Bar() {
println("concrete bar")
}
type Interface1 interface {
Foo()
}
func (i Interface1) Bar() {
println("interface bar")
}
type Interface2 interface {
Foo()
Bar()
}
func main() {
var c Concrete
var i1 Interface1 = c
var i2 Interface2 = i1
i2.Foo() // prints "concrete foo"
i2.Bar() // prints... what?
}
The core of the matter is that only concrete types are recorded when you put something into any kind of interface. If interface types were recorded as well, then there are a few unfortunate consequences.
First, either you only remember the most recent type the thing had (that is, the last interface it came from) and you’d forget something’s original type, or you have an arbitrarily deep stack of types passed along with the value.
While forgetting the previous types could produce working code, interfaces would no longer be particularly useful.
Keeping the entire stack of types that something has been labeled by also adds a lot of complexity, and it would be very hard indeed to keep track of what methods were available. Can you get something that has the method .Foo() out of this interface{}? Well, maybe, but the number of times you’d have to type assert it would depend on the control path up until that point.
Second, even if you did remember all the interfaces that have labeled your value until this point, there is a good deal of ambiguity. Whose .Foo() method are we to use? I suppose the last label that had such a method, but this is complicated and would be extremely error prone.
This is all made moot by the fact that anything you would be able to do by defining methods on interfaces can already be done using existing go syntax. Taking something that is an interface and giving it extra behavior is straightforward.
type MyInterface interface {
Foo()
}
type MyWrapper struct {
MyInterface
}
func (mw MyWrapper) Bar() { ... }
Here we are in essence recording the type stack ourselves without much effort. If we’ve got a “var x MyInterface”, then “y := MyWrapper{x}” is sufficient to create a new value that will invoke the original concrete type’s .Foo() method and the MyWrapper’s .Bar() method.
The moral of the story is, allowing methods to be defined on interfaces gives no extra power and adds a lot of extra confusion.
People I work with recognize my computer easily: it's the one with nothing but yellow windows and blue bars on the screen. That's the text editor acme, written by Rob Pike for Plan 9 in the early 1990s. Acme focuses entirely on the idea of text as user interface. It's difficult to explain acme without seeing it, though, so I've put together a screencast explaining the basics of acme and showing a brief programming session. Remember as you watch the video that the 854x480 screen is quite cramped. Usually you'd run acme on a larger screen: even my MacBook Air has almost four times as much screen real estate.
The video doesn't show everything acme can do, nor does it show all the ways you can use it. Even small idioms like where you type text to be loaded or executed vary from user to user. To learn more about acme, read Rob Pike's paper “Acme: A User Interface for Programmers” and then try it.
Acme runs on most operating systems. If you use Plan 9 from Bell Labs, you already have it. If you use FreeBSD, Linux, OS X, or most other Unix clones, you can get it as part of Plan 9 from User Space. If you use Windows, I suggest trying acme as packaged in acme stand alone complex, which is based on the Inferno programming environment.
Mini-FAQ:
acme -f /mnt/font/Monaco/16a/font you get 16-point anti-aliased Monaco as your font, served via fontsrv. If you'd like to add X11 support to fontsrv, I'd be happy to apply the patch.
If you're interested in history, the predecessor to acme was called help. Rob Pike's paper “A Minimalist Global User Interface” describes it. See also “The Text Editor sam”
Correction: the smiley program in the video was written by Ken Thompson. I got it from Dennis Ritchie, the more meticulous archivist of the pair.
Notes to myself more than anything, and not really specific to Go (but that’s where I was using it).
To watch the memory usage of a process with pid PID:
while [ 1 ] ; do grep VmSize /proc/PID/status ; sleep 10 done
To watch the number of file descriptors being used:
while [ 1 ] ; do sudo lsof -p PID | wc -l ; sleep 10 done
In much of the programming universe, the preferred method of synchronization between two or more concurrent processes is the mutex. And for good reason: mutexes (mutices?) provide a very simple tool that is easy to understand, and once you acquire that understanding you can use it to build arbitrarily complex concurrent systems.
Eventually.
The problem is that what you want as the programmer is rarely limited to exactly what a mutex gives you. Most of the time you need something a bit more complex, and although the more complex operation can be built out of mutexes, small errors become huge bugs which can be difficult to fix or even just observe (heisenbugs).
In this post I will demonstrate how to build a useful real-world concurrent system, first using mutexes and then using the more advanced tools that go offers.
The system in question is a notification multiplexor. One process, which I’ll call the Listener, will receive notifications from an outside source. Some number of other processes, which I will call the Subscribers, need to collect these notifications.
// for simplicity, our notifications will just be simple strings
type Notification string
// and different subscribers tell us about which ones they want via a filter
type NotificationFilter func(string)bool
// a PollFunc gets all outstanding notifications for its subscriber
type PollFunc func() []Notification
type Notifier struct {
// we'll embed a mutex in the Notifier, so it can be locked and unlocked
sync.Mutex
// queues is the list of outstanding notifications for each subscriber
queues [][]Notification
filters []NotificationFilter
}
func NewNotifier() *Notifier {
return new(Notifier)
}
func (n *Notifier) Subscribe(filter NotificationFilter) (PollFunc) (
n.Lock()
defer n.Unlock()
index := len(n.queues)
n.queues = append(n.queues, []Notification{})
n.filters = append(n.filters, filter)
return func() (results []Notification) {
n.Lock()
defer n.Unlock()
results = n.queues[index]
n.queues[index] = n.queues[index][:0]
}
}
func (n *Notifier) Notify(not Notification) {
n.Lock()
defer n.Unlock()
for i, filter := range n.filters {
if filter(not) {
n.queues[i] = append(n.queues[i], not)
}
}
}
Seems pretty straight forward, right? It is. This is a simple system, and each of the operations that acquire the mutex are finite time and efficient (assuming that the filter function is too).
There are a few problems, here.
Foremost, and the concurrency sharp-shooters out there will have already noticed this, is that polling the notifier is a busy-wait operation. Even if your program only polls once every 20 seconds, that is still wasted cycles every 20 seconds if no notifications have come in.
And what if before those 20 seconds have elapsed, a whole stack of notifications have queued up? Perhaps a condition variable that unlocks when some condition has been met (like, the number of notifications is not zero). But waiting on a condition variable blocks your entire goroutine.
Go’s channels and the select{} statement provide an elegant response to these questions.
The method to accomplish this goal that I will show here is something often called a mux(), which is short for multiplexor.
To give a little go background, one of the ways that the current go runtime is so effective is that it will multiplex goroutines (Gs) to some set of available processes (Ms, short for machines). A given running go program will have some number of Ms, and some set of Gs that are not currently blocking. That is, the Gs aren’t performing a channel send/receive, aren’t trying to do some kind of I/O (networked or local), aren’t blocked on a semaphore acquire, or for some reason aren’t unable to make progress until something else happens.
When one of the running Gs hits a blocking operation, it is removed from its M and replaced with another G that is ready to go. This kind of CPU time-sharing is usually expressed in terms of coroutines, and that provides the basis for the word goroutine.
We’re going to do something similar with the notification system, except instead of Ms we can have the notifier’s goroutine, and instead of Gs we have the various things that can happen, which for our example are “new notification” and “tell me about a notification”.
Also, in a previous post I discussed stacked channels. Moving forward, I’m assuming the reader either knows how they work or does not care.
// the stacked channel joins notification sets by appending the slice
type NotificationChan chan []Notification
func (nch NotificationChan) Stack(ns []Notification) { ... }
func JoinNotifications(ns1, ns2 []Notification) (ns3 []Notification) {
ns3 = append(ns1, ns2...)
return
}
type NotificationFilter func(Notification) bool
type newSubscriber struct {
filter NotificationFilter
res NotificationChan
}
type Notifier struct {
// the listener sends new notifications on this channel
Incoming NotificationChan
filters []NotificationFilter
chans []NotificationChan
newSubscribers chan newSubscriber
}
func NewNotifier() (n *Notifier) {
n = &Notifier{
Incoming: make(NotificationChan, 1)
}
go n.mux()
}
func (n *Notifier) Subscribe(filter Filter) NotificationChan {
ns := newSubscriber{
filter: filter,
res: make(chan NotificationChan),
}
n.newSubscribers <- ns
return <-ns.res
}
func (n *Notifier) mux() {
for {
select {
case ns := <-n.newSubscribers:
n.filters = append(n.filters, ns.filter)
ch := make(NotificationChan, 1)
n.chans = append(n.chans, ch)
ns.res <- ch
case nots := <-n.Incoming:
for _, not := range nots {
for i, filter := range n.filters {
if filter(not) {
n.chans[i].Stack(not)
}
}
}
}
}
}
With a mux()er like this, instead of a system of polling or condition variables, we get a channel. The mux() goroutine takes care of moving notifications coming from the listener (via n.Incoming) to the subscribers.
Also, since adding subscribers touches a data structure that sending notifications also touches, new subscribers come in on a channel so they can be handled next to the incoming notifications in a single goroutine.
And the greatest benefit is that the subscribers can select on their own notification channels as well channels for communicating with other processes. No special condition magic needs to be performed - select{} gives you everything you need.
Sometimes a go programmer will wish for an infinitely buffered channel. Go does not offer any such construct, though by creating two channels and a goroutine to move data between them, it is possible to have infinitely buffered channel semantics.
Sometimes what people actually want is a channel that never blocks and never forgets. This isn’t quite the same as a channel with an infinite buffer. I didn’t mention anything about preserving the original message order, for one.
What you can do in the situation I describe is use something I’ve been calling a “stacked” channel. It’s a buffered channel with a special send operation and whose value type has a meaningful “join” function.
type Thing anything
func JoinThings(thing1, thing2 Thing) (thing3 Thing) { ... }
type ThingChan chan Thing
func NewThingChan() ThingChan {
return make(ThingChan, 1)
}
func (tch ThingChan) Stack(thing1 Thing) {
for {
select {
case tch <- thing1:
return
case thing2 := <- tch:
thing1 = JoinThings(thing1, thing2)
}
}
}
If it’s not immediately clear how stacking works, take a minute to try to figure it out before reading the explanation below.
The stacked channel allows non-blocking sending. That is, whenever a goroutine wants to send to this channel using the .Stack() method, it will complete quickly (provided that the join function completes quickly).
This non-blocking occurs because when the select{} statement is executed, there are two possible states for the channel. Either its buffer is full or its buffer is empty. If the buffer is empty, the new value will be put in immediately. If the buffer is full, the value will be picked off, combing with the new value and put back on.
It is possible that another goroutine stacks something in the meantime, and it will have to pick off another value to join and put back. With a fair scheduler, every goroutine attempting to stack will make progress quickly, relative to the the number of goroutines in contention. This progress comes about because every time a goroutine has to loop back and try again, there must have been another goroutine that succeeded in leaving a value on the channel.
This stacking technique has definite real-project application. I work for a private corporation on a public project called skynet. With skynet, client programs need to be notified about new services as they come available. Sometimes these notifications can come faster than a client can ask about them, and they stack up. We use a stacked channel to collect the notifications into bundles without stalling out the notification system.
Here’s a play example: http://play.golang.org/p/MEp87YesU6
My son now needs a bedtime story, whispered in the dark, to go to sleep. My wife and I both love good story telling. She even took a course on it once, and told a story to an audience as the final project. We go to le Nuit des Contes every year here in Lausanne, and I’ve picked up some tips from watching the (literally) professionals there. A key to oral story telling, certainly for small children, is to use a structure with repeating sounds and phrases that they can get wrapped up in.
In order to have these some day to look back at, I’m going to start writing down summaries of stories I tell. If one is good enough to develop and retell, perhaps one day I’ll tell it at the Nuit des contes!
Our 1974 VW Type 2 camper van (“Bep” is his name) would be the star of every story if Elio got to choose. Instead, we offer him a choice of three characters and then go from there. The key, I find, is to start slowly, describing the character, throwing in some fun details right away. This gives you time to race ahead in your mind and choose a rough storyline. The easiest is to choose the end state first, so you know where you are trying to get to. Then, like a dot to dot painting, you need to fill in a few intermediate hops along the way. These are attempts the character makes at achieving the goal, or increasingly dire straights the character finds himself in. These stretch out the story, but more importantly, give it a verse/chorus/verse/chorus/verse structure, which is where the real magic comes from. And the rhythm necessary to put a fidgety 2-year old kid to sleep, as well, which is the point afterall!
What do I mean by verse/chorus? The chorus is the catch-phrase, the repeated element that signals another loop around. It gives the story rhythm and momentum. The verses carry the story forward, so that you get to where you are trying to go and you get that nice satisfying conclusion.
So here are several stories that I’ve told so far:
I think it’s time to bring the guestbook to the next level, and that means users and sessions. This post will show you how to handle user registration and authentication. Let’s get started!
The first thing we’re going to do is create a type to store the information of the user. So what do users have? Well, an ID to identify them in the database, a username, and a password. To make this a little more fun, we’re also going to store the number of times they’ve posted on the guestbook. So here’s our type:
<figure class="code"><figcaption>user.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Now lets define some functions to help hash the password and set it on the user and and authenticate a user given a username and password.
<figure class="code"><figcaption>user.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Now lets work on the handler to log them in.
The login handler should be pretty simple. All we have to do is get the username and password from the form POSTed to the handler, and pass it to our Login function which will grab the user from the database and authenticate the credentials.
<figure class="code"><figcaption>handlers.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
But we ran into some trouble. When should we display the template for the form? Where do we store that the authentication was correct? Fortunately it’s not too hard to fix these problems. Lets handle the displaying of the template part first.
The login handler is really two actions. When a GET request is passed to the handler it should display a nice form, but when a POST request is passed to the handler it should authenticate a user. These different actions based on the verb used on the URL means we should dispatch to the correct handler in the router rather than the handler itself. Lets write the simple form displaying template first.
<figure class="code"><figcaption>handlers.go </figcaption>1 2 3 4 5 6 7 8 9 | |
The code was getting “smelly” because it wasn’t nice to have global variables storing the templates, so it wasn’t too hard to whip up a simple function to compile templates and cache them on the fly. Here’s what that looks like, and the new handler using it:
<figure class="code"><figcaption>template.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 | |
At this point I had a working login page that would 404 when you clicked Login. There were some smaller changes made around to clean things up that you can see in this commit (I have annotated the commit to include some comments on the changes.) Let’s add the login form handling now.
A session is just some data attached to some id that you hand the client in a cookie. This way when a client requests a page, you can look at the cookie value and get the id for the data and load up the data for that request. Tada! Sessions! For our implementation of sessions, we’re once again going to use the excellent gorilla package for sessions. It lets you use different stores for the backend data, and in this case we’re just going to use a cookie store. This stores all the data in the cookie the client sends to you. This does mean that the user can tamper with the cookie, but the data is verified using a secret value and a hash, and can optionally be encrypted with another secret value. For this I’m just going to use a store that doesn’t encrypt the data: after all, the data the store uses is open source.
<figure class="code"><figcaption>main.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 | |
So we defined a cookie store, now let’s add grabbing the session to the context.
<figure class="code"><figcaption>context.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 | |
The last thing we need to do is make sure the handlers save the session when they’re
done with it. Unfortunately this causes a problem. Saving the session requires
modifying the headers of the response, and if the handler has already started
outputting data, the headers have already been sent and that ship has sailed.
Theres two approaches to solving this problem. The first is to just make sure
in each handler to save the session before writing anything to the ResponseWriter,
which can be a little verbose and error prone but provides the best performance.
The second is to use the fact that a ResponseWriter is an interface and use our
handler type to substitute in a buffered ResponseWriter that stores all the data
and header information written to it, so that it can be output at the end all at once.
I wrote a package to help with the second option so it’s clearly the one I prefer.
Here’s how we can hook that up:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
All we do is create an httpbuf.Buffer and use that as our handler, finishing
with a call to its Apply method. With that, we can set and grab session values
in the handlers by just interacting with ctx.Session, and everthing will be
saved when we’re done.
Now that we have sessions, we know where we can store the user. Lets write the login handler for the user then.
<figure class="code"><figcaption>handlers.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Note that we have to register the bson.ObjectId type with the gob package
because the cookie store uses gob to store the data for the session.
Well, now we log in people and store it in the session, but it’d be nice if that
was reflected somehow in the user interface and if the context included information
about the logged in user. Lets do some work on the context and handlers to fix this.
First, we’re going to add a *User to the context that gets filled in based on the
id we stored in the session.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Now we just have to add the context to the value we pass in to templates to be executed and hook up the templates. This commit shows the details of that, including adding a logout handler, and fixing some minor issues with the code.
The last two features we need are letting people register and increasing a persons post count when they post. Let’s work on registration first. Registration works just like logging in, so we need to create a template and two handlers.
<figure class="code"><figcaption>handlers.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
The register.html template is very similar to the login template. If you really
wan’t to see it, you can find it at this commit. Incrementing
the post count is super simple. In the sign handler, we just add
ctx.C("users").Update(bson.M{"_id": ctx.User.ID}, bson.M{
"$inc": bson.M{"posts": 1},
})
So after all that we have a login/user registration system, and a session tied to a context for storing whatever data we want. Hopefully with this guide you can extend it to meet the needs of whatever webapp you’re writing. Thanks for reading so far, and be sure to register and leave a comment on the gostbook or right below if you liked it.

<root>The resulting package codes could then be stored in a folder named after the interface name (in the above example "skd") as composites.go, segments.go, groups.go, etc. Every time there's a new version of the grammar XML file, edigo must be used to regenerate the said files.
<source>Visual Services 5 - XML Generator
<version>1</version>
<interface description="Yada yada blah." name="SKD" release="9" version="02">
<transactions>...list of transactions...</transactions>
<messages>...list of messages...</messages>
<groups>...list of groups...</groups>
<segments>...list of segments...</segments>
<composites>...list of composites...</composites>
</interface>
</source></root>

This week we released version 1.7.1 of the App Engine SDK. It includes some significant updates specific to the App Engine runtime for Go.
The memcache package has had some additions to its Codec convenience type. The SetMulti, AddMulti, CompareAndSwap, and CompareAndSwapMulti methods make it easier to store and update encoded data in the Memcache Service.
The bulkloader tool can now be used with Go apps, allowing users to upload and download datastore records in bulk. This is useful for backups and offline processing, and a great help when migrating Python or Java apps to the Go runtime.
The Images Service is now available to Go users. The new appengine/image package supports serving images directly from Blobstore and resizing or cropping those images on the fly. Note that this is not the full image service as provided by the Python and Java SDKs, as much of the equivalent functionality is available in the standard Go image package and external packages such as graphics-go.
The new runtime.RunInBackground function allows backend requests to spawn a new request independent of the initial request. These can run in the background as long as the backend stays alive.
Finally, we have filled in some missing functionality: the xmpp package now supports sending presence updates and chat invitations and retrieving the presence state of another user, and the user package supports authenticating clients with OAuth.
You can grab the new SDK from the App Engine downloads page and browse the updated documentation.
公式サイトの更新を反映しました。
Buffer type. On its own, the name Buffer isn't very descriptive, but when combined with its package name its meaning becomes clear: bytes.Buffer. If the package had a less descriptive name, like util, the buffer would likely acquire the longer and clumsier name util.BytesBuffer. -r flag that provides a syntax-aware search and replace, making large-scale refactoring easier.)$GOROOT/src/pkg or $GOPATH/src) in which the package's source code resides.websocket package from the go.net sub-repository has an import path of "code.google.com/p/go.net/websocket". The Go project owns the path "code.google.com/p/go", so that path cannot be used by another author for a different package. Because the repository URL and import path are one and the same, the go get command can fetch and install the package automatically."google"."net/http" contains package http. This is not a requirement - you can make them different if you like - but you should follow the convention for predictability's sake: a user might be surprised that import "foo/bar" introduces the identifier quux into the package name space.GOPATH to the root of their source repository and put their packages in directories relative to the repository root, such as "src/my/package". On one hand, this keeps the import paths short ("my/package" instead of "github.com/me/project/my/package"), but on the other it breaks go get and forces users to re-set their GOPATH to use the package. Don't do this.I’ve seen many tutorials on the internet about how to use templates in Go. They typically concentrate on the syntax of the template and don’t go in to the details of how they’re constructed and used in Go code. That’s why this article is about what a template really is, and how to use them in your code.
Back before Go 1, the text/template package was different. The real major difference was the package defined two major types: a template and a template set. At some point the library authors decided to merge them into one, the Template type.
I like to think of a template as a collection of templates, with one promoted as the “default” template. The default template is the one that gets used when the execute method is called. Internally, a template contains a map of all the other templates it is linked with, and each one of those templates contains the same map. This makes the namespace of a template flat. It sounds really confusing, so hopefully we can make it easier with some examples and implications.
So given that a template is really a set of templates with a mapping of all the template names in the set to the templates (phew), what can we expect in how we work with it?
Every template in the set can be called by any other. Because every template shares the same map of name to templates, any template can call any other templates. This is a pretty simple.
You can’t have two templates with the same name. This is also pretty obvious but bears stating. Because the namespace is flat, two template with the same name would cause a collision. The package doesn’t allow you to add a template to a set under a name that already exists.
Theres no such thing as a subtemplate. Because the namespace is flat, you can’t really have one template be a subtemplate of another. Because every template is accessible from every other template, the concept of one template owning another isn’t really defined. This isn’t to say you can’t use templates like subtemplates, its just that theres no mechanism enforcing this in the package.
Lookup is idempotent. This means that calling t.Lookup("name").Lookup("name")
is the same as t.Lookup("name"), as long as "name" exists in the template. This
is because every template shares the same map of template name to template. When we
lookup a specific one, it still has the same map to lookup the next one. This is
a handy property because it makes it always safe to call Lookup regardless of the
current state of the template.
Here’s some common problems with the template package that people run into:
ParseFiles and its friends add the template under the name of the file. This means
if you do template.New("base").ParseFiles("foo.html") and try to execute it, you will
have an empty template. The template was read and parsed from “foo.html” and added to the
template under that name. This means you have to either do a .Lookup("foo.html") or
change the name in New to “foo.html”.
Not just the name of the file, the basename of the file. This means if you
try to do .ParseFiles("a/main.html", "b/main.html") you’ll run into problems
because the two files share the same basename. It returns an error saying that
you can’t redefine the template named “main.html”.
Functions must be added before parsing. During parse time, the template package
needs to know all the identifiers that could be used to parse a template correctly.
This means that you need to set the function map before you do any parsing.
This can make the code a little longer, especially when you start with
a simple template.ParseFiles and need to add functions to it.
Now that we know more about how templates work and some common gotchas, lets look at some code and have a quiz. Here’s how the quiz works: I’ll show you a piece of sample code consisting of some files, and you tell me the output. The answers are at the bottom of this post.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1
| |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1
| |
1
| |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Question 1: Nothing. The “foo” template is the “active” template and it’s empty. Did you read the Gotchas?
Question 2: “Hello World!”. Nothing tricky about this one. Interesting fact: if we reversed the order of the parsed files it would be the same output, even though it does something totally different. (Why?)
Question 3: A panic. We don’t have the functions in the template at the time of
the parsing, so an error is returned and Must causes a panic. This is Gotcha number 3.
So how did you do? I admit, some of the questions were tricks and subtle so it’s ok if you got some (all) of them wrong, but all of them were inspired by common problems I’ve seen people have. Templates are actually pretty simple, but they have some non-obvious properties that require some care in how they are created and used in your code.

Ok, so I’ve not managed to keep this updated… yeah, I hate meta-blog posts as much as anybody, so I’m going to keep this short - timetabled blogging clearly doesn’t work for me, so I’m officially making no promises about blogging ever again, I promise, even if that is a paradox ;-)
I’ve been making good progress on weak, though I have been totally focused on optimising move generation so far to the point that the engine doesn’t actually play yet. This is after I switched from go to C since performance in the go version was so poor that I simply couldn’t continue. I have now got to the point where I’m vaguely happy with performance, so I’m going to work on actually making the engine play. I also plan to back-port to go at some point. It’ll be interesting to see how it looks after all the optimisations I’ve applied since going to C.
The switch isn’t necessarily a poor reflection on go, rather a combination of it being a very young language, and the fact that go is pretty much an unsuitable choice for this project. A chess engine is quite an unusual piece of software in any case, as it really does rely on pedantic optimisation more than a lot of other software might, and certain handy assembly instructions (bit scan forward/backward, pop count.)
Since I have used several ideas from stockfish for optimising weak, I have moved to a GPLv3 license and officially acknowledged weak as a stockfish derivative. The degree of derivation right now is small, by no means have I copied code wholesale (the hours and hours spent debugging many very evil bugs is a testament to that), but there are certain portions of code which have been heavily influenced by my having scoured stockfish’s code, and a few portions of code which are essentially direct C ports of portions of stockfish (written in C++), hence the necessity of this move.
Moving to this arrangement also affords me the opportunity to mine stockfish for ideas as much as I like. Given the incredible quality of stockfish, that is quite useful to say the least. Regardless, I am not interested in simply porting the code to C, so it’ll be a matter of mining the code for ideas and applying them to weak.
Hopefully I’ll put up a decent post about chess engine development at some point. In other news, I am enjoying my time in startup-land, having just spent a week in Greece working with some of my Grecian colleagues in a slightly nicer climate than dear old Blighty.
If you do DNS for too long everything looks like 53.
In this "trace" I'm showing the logging of fksd when I add a zone, try to list it as a non-existent user miekg (which fails), add the user miekg and list it again. User are identified by the key in the TSIG record, their password is the shared secret.
The "config files" from nsupdate can be found in the github repo of fksd. The nsupdate commands are preceded with a %, extra comments are preceded with #:
./fksd -log
# add a zone as the superuser (defaults to root)
% nsupdate -vd addzone
2012/08/07 21:48:31 fksd: config command
2012/08/07 21:48:31 fksd: config command ok
2012/08/07 21:48:31 fksd: config: READ miek.nl. /home/miekg/g/src/dns/ex/fksd/z/miek.nl.db
2012/08/07 21:48:31 fksd: config: added: READ miek.nl. /home/miekg/g/src/dns/ex/fksd/z/miek.nl.db
# list the zones in the server as the user miekg (this fails)
% nsupdate -vd listzone-miekg
2012/08/07 21:48:35 fksd: config command
2012/08/07 21:48:35 fksd: non config command (tsig fail): dns: bad signature
# add the user miekg (only the superuser may do this)
% nsupdate -vd adduser-miekg
2012/08/07 21:48:39 fksd: config command
2012/08/07 21:48:39 fksd: config command ok
2012/08/07 21:48:39 fksd: config: ADD miekg. with bWlla2c=
# list the current users
% nsupdate -vd listuser
2012/08/07 21:48:43 fksd: config command
2012/08/07 21:48:43 fksd: config command ok
2012/08/07 21:48:43 fksd: config: USER root.: c3R1cGlk
2012/08/07 21:48:43 fksd: config: USER miekg.: bWlla2c=
# Again, list the zones as the user miekg, now it works
% nsupdate -vd listzone-miekg
2012/08/07 21:48:51 fksd: config command
2012/08/07 21:48:51 fksd: config command ok
2012/08/07 21:48:51 fksd: config: LISTThat last command now works, before we got a "dns: bad signature" error.
The user management will be kept simple. The superuser can do everything, other users can use: write, list or drop, but this is currently a (minor) to do.
Last time we made a little guestbook application, but there were a couple pain points. We had to have some boiler plate at the top of all of the handlers, and errors were handled by copying the same line of code everywhere. We also had fixed url paths hard coded in handlers and templates. Let’s see how we can fix that.
A lot of the boiler plate in the handlers last time had to do with the database for each request, so let’s start by cleaning that up. How we do this is by creating a type that will have the context for the request.
<figure class="code"><figcaption>context.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
A context is the general context the request will use to make decisions, bundled up with the handles to the resources it needs to perform actions. Right now we only have the database. Let’s change our handlers to use the new context.
<figure class="code"><figcaption>main.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | |
Now thats wonderful, but it looks like we just made it worse.
To fix this, we’re going to create a new handler type, and give it a
ServeHTTP method. This new handler type will handle creating/closing
the context, and handling any errors that arise. Here’s the definition:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The handler type is a function type, meaning any function with that signature
can be cast to that type. We define a method on the function (I know!) so that
the net/http package can use it as though it were any other handler. We’ve
already been doing something very similar to this already. When we called the
http.HandleFunc function in our main.go, we’ve been using our functions
as the type http.HandlerFunc which defines a ServeHTTP method, just like ours.
See, it’s not so bad. Here’s what the new handlers look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
Much better! Let’s commit that.
The other pain points, hard coded urls, and checking the request method,
are going to be handled by more advanced routing. For this, we’re going
to use the execllent gorilla web toolkit, specifically the
gorilla/pat package. I really like the simple API it provides
with easy parameter capturing from the url. It’s very easy to use with the
net/http package:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
One important and easy to miss detail is we now pass the router in as the
second argument to the http.ListenAndServe call. Now we can remove the check
that the method is POST in the sign handler, as the router takes care of that
for us. Lets move on to fixing the hard coded entries.
If you’ll notice, we gave the handlers a .Name call. The gorilla/pat
package returns a *mux.Router for us to work with. Using that we can have the
router rebuild urls from the names. For example, if we wanted to grab the url for
the index page, we could use
r.GetRoute("index").URL()
but since r is inaccessable outside the main function, we have to move it
into a higher scope. Let’s do that.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
And now we can update the sign handler
<figure class="code"><figcaption>handlers.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 | |
To reverse inside the template, we could either remember to pass the router in as part of the template context on every invocation, or we could add a function to the template. Since keeping track of the router through nested templates and scope changes is a daunting task, adding a function to do the reversing is a better option. Heres that function:
<figure class="code"><figcaption>main.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 | |
We choose to have the function panic on errors because any incorrect reversal
is a programmer error. We also accept a variadic number of interface values because
sometimes we need to have a parameter in the reversal that is an integer, like the
year on the blog post url, and the URL function takes strings.
So rather than force the template to do the conversion, or the function executing the template, we
just convert everything to a string by calling fmt.Sprint on it. Then we have
to add this function to the template.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Theres a tricky point here: the template package will error when trying to parse a template and it finds a function invocation to something undefined. That means we have to add our function map to the template before we add the files to parse. We write a little helper function to do this correctly. Now we can update the template to use it.
<form action="{{ reverse "sign" }}" method="POST">
Let’s update the sign handler to use the reverse function too.
http.Redirect(w, req, reverse("index"), http.StatusSeeOther)
Pain: consider yourself eliminated.
Next up, we’re going to do more with the context type we created, and make the guestbook a little more web 2.0. As always, the source to the gostbook is up on github.
I'm writing a nameserver called fksd (Funkensturm daemon), which is currently in a prototype stage (but the code is available at github).
In this server I'm pursuing some interesting directions in nameserver development, such as the dynamic configuration as provided by BIND10.
BIND10 uses http(s), but I think using DNS packets is more in line with a nameserver, so I opted for that route.
With fksd you can use packets (which will be TSIG signed in the future tomorrow) to configure the server. The only configuration possible at the moment is adding a zone. Such a packet needs to have a TXT record like the following in its AUTHORITY SECTION:
ZONE. IN TXT "READ miek.nl. /path/to/zone"Using the AUTH. section means we can re-use nsupdate (#win).
The current dev. version of fksd listens on port 1053 for real dns queries and on 8053 for configuration queries. Lets start the daemon and query for miek.nl MX:
$ ./fksd -log
<in other terminal>
$ dig @127.0.0.1 -p 1053 mx miek.nl
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 1945
...Indeed, SERVFAIL, because miek.nl. isn't loaded. Lets fix that (-vD is crucial otherwise it won't work for some reason):
$ nsupdate -vD
> server 127.0.0.1 8053
> zone ZONE.
> update add ZONE. 60 IN TXT "READ miek.nl /home/miekg/g/src/dns/ex/fksd/z/miek.nl.db"
> send
; Communication with server failed: timed outThat last error is because I'm lame and do not send a reply message (will be done in the future). Meanwhile fksd logs:
2012/08/06 23:13:27 fksd: config commmand
2012/08/06 23:13:27 fksd: config: READ miek.nl. /home/miekg/g/src/dns/ex/fksd/z/miek.nl.dbWhen I now query for miek.nl MX, I get:
$ dig @127.0.0.1 -p 1053 mx miek.nl
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31060
...
;; ANSWER SECTION:
miek.nl. 345600 IN MX 20 mail.atoom.net.
miek.nl. 345600 IN MX 40 mx-ext.tjeb.nl.
;; AUTHORITY SECTION:
miek.nl. 345600 IN NS ext.ns.whyscream.net.
miek.nl. 345600 IN NS open.nlnetlabs.nl.
miek.nl. 345600 IN NS omval.tednet.nl.
miek.nl. 345600 IN NS elektron.atoom.net.
...The config will be put in some kind of journal in json format (just like BIND10...), which is also "a future todo"(TM). But for now: this seems to work very nice - now the only thing left is to implement the rest of this authoritative nameserver.
<script src='https://raw.github.com/axx/GolangHighlighter/master/shBrushGo.js' type='text/javascript'/>Then use either "go" or "golang" as alias when you insert golang code on your blog:
<pre class="brush: go">package mainThis will be rendered as:
import "fmt"
func main() {
fmt.Printf("yoohoo!")
}</pre>
package mainI hope someone else finds it useful. Please drop a comment if you have some suggestions on how to improve it.
import "fmt"
func main() {
fmt.Printf("yoohoo!")
}




After reading a neat article whose title I stole about making a guestbook app in Flask, I decided to see how it would compare to my favorite language of the year, Go. So here’s my take.
Let’s create a new directory to hold the project. I’m gonna host the code on github so let’s make the local directory match the import path.
$ cd ~/Code/go/src
$ mkdir -p github.com/zeebo/gostbook
$ cd github.com/zeebo/gostbook/
$ git init
Initialized empty Git repository in /Users/zeebo/Code/go/src/github.com/zeebo/gostbook/.git/
Note that ~/Code/go is a directory in my GOPATH environment variable, the only
piece of configuration I need to do to have the build tool know how to fetch and
build any code that uses these conventions. Lets put in a little hello world code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
This registers a handler that will match any path and write
Hello World! in the response. Building and running this code
runs a server that listens on port 8080, so lets visit it.
$ go build
$ ./gostbook &
[1] 39629
$ curl localhost:8080
Hello World!
$ kill 39629
Neat!
Let’s do our source control duty, and make a commit with our super simple app.
$ cat .gitignore
*
!.gitignore
!*.go
!*.html
$ git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# .gitignore
# main.go
nothing added to commit but untracked files present (use "git add" to track)
$ git add .
$ git commit -m 'initial commit'
[master (root-commit) de0b184] initial commit
2 files changed, 21 insertions(+)
create mode 100644 .gitignore
create mode 100644 main.go
The next step is to put templates in. Lets make a template directory and some basic templates in there. I’ll steal the templates from Eevee’s post and change them to use the built in html/template package from the standard library. Here’s the source:
<figure class="code"><figcaption>templates/_base.html </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 11 | |
Updating the Go code is a little more work, but not much.
<figure class="code"><figcaption>Template World - main.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Building and running again, we see it’s working:
$ go build
$ ./gostbook &
[1] 39918
$ curl localhost:8080
<!DOCTYPE html>
<html lang="en">
<head>
<title>Guestbook</title>
</head>
<body>
<section id="content">
<h1>Guestbook</h1>
<p>Hello, and welcome to my guestbook, because it's 1997!</p>
<ul class="guests">
<li>...</li>
</ul>
</section>
<footer id="footer">
My Cool Guestbook 2000 © me forever
</footer>
</body>
</html>
$ kill 39918
Let’s be diligent and make another commit. On to data!
Go has many database bindings but the one I find easiest to work with would be MongoDB with the excellent mgo driver. Let’s create our data model.
<figure class="code"><figcaption>Database entry - entry.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
We just create a struct with some fields. The mgo driver uses runtime
reflection to look up the information about the struct for setting and reading
the values. For the ID field add some tags to it to instruct bson to omit it if
the value is empty, and name it _id when serializing, to have MongoDB pick the
id for us on insertion, and name it what it’s expecting. We also provide a
NewEntry function for creating an Entry at the current time.
Now lets add support to the handler.
<figure class="code"><figcaption>Databased up - main.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
Interacting with the databse requires a little boilerplate in the handler,
but this can easily be removed by clever use of Go’s interfaces. The net/http
package will serve anything with a ServeHTTP(ResponseWriter, *Request) method,
so you can decorate handlers by wrapping them in simple types that implement
that interface. Doing that is left as an exercise to the reader :)
Here’s how we change the template:
<figure class="code"><figcaption>templates/index.html </figcaption>1 2 3 4 5 6 7 8 | |
Notice we don’t worry about any kind of injection. The html/template package is super awesome and handles that by knowing what it’s outputing and the context in which the data is being used. If you’re in an html context, it will escape the html properly. If you’re in a script or url context, it knows and will apply the appropriate esacping. No modifying the data in the database. No “sanitizing”. Just doing the right thing, every time.
Time to add the handler to sign the guest book. Let’s start with the html for the form.
<figure class="code"><figcaption>templates/index.html </figcaption>1 2 3 4 5 6 7 | |
And now the handler:
<figure class="code"><figcaption>sign.go </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
All we need to do is add a single line to main.go to make it handle the new handler:
http.HandleFunc("/sign", sign)
And we can sign, and view our guestbook. Lets commit again.
Now the astute reader will notice a couple little pain points.
We had to check in the sign handler if the method was POST. This can
be fixed by using a more sophisticated muxer than the built in one in net/http.
Like all good packages in Go, all of these things are just interfaces and so you
can swap them out with many community driven packages. An exellent one is the
gorilla muxer at code.google.com/p/gorilla/mux.
We had to hard code the urls. Once again, this is solved by using a more sophisticated muxer. code.google.com/p/gorilla/mux supports building urls from names you give to the routes.
Boilerplate in the handlers to specify a database/collection every time.
I typically solve this how I wrote earlier by making a type that implements
the ServeHTTP method and passes in a request context containing everything
I need to use for that request, including sessions and database connections.
It’s only a couple lines of code to make, but outside the scope of this
post.
Other than that, I found it to be pretty painless and about as easy to do as the Flask version. Considering this is a statically typed compiled language, that’s quite the feat.
It wouldn’t be useful if it wasn’t deployed. Fortunately, Go compiles down into a static binary. This can be shipped to any system that it was compiled for, and just ran. Go also allows you to easily cross compile for any system, so thats a non-issue as well. The built in web server is comparable in performance to things like Apache and nginx from my tests. So for most cases, it’s as simple as running a binary and either proxy passing it through from your front end server, or just letting the world hit it directly.
But, since that’s not cool enough, we’re also going to deploy on Heroku.
Unfortunately, Go isn’t a supported platform on Heroku. Fortunately, it’s just a buildpack away. The Cedar stack is excellent and allows you to run any binary you want to host your web site, so we just have to tell Heroku how to build our code. I’m a little biased so I’m going to use the buildpack I modified to do this, although there are alternatives.
The cool part about hosting our code on github is that anyone with Go installed can just grab it with a single command:
go get github.com/zeebo/gostbook
That will download, compile, and install a binary named “gostbook” in our bin directory in our GOPATH. The buildpack I created uses this to build the code we’ll be deploying. First we make a little file that describes how to do it, and a Procfile to describe what to run:
<figure class="code"><figcaption>.heroku </figcaption>1 2 | |
1
| |
Then we have to be nice and listen on the port Heroku tells us to. This is a one line change:
if err = http.ListenAndServe(":"+os.Getenv("PORT"), nil); err != nil {
Lastly, we have to dail out to the mongo config they ask too:
session, err = mgo.Dial(os.Getenv("DATABASE_URL"))
I use DATABASE_URL as the key. We’ll have to set it later in the deployment.
Let’s commit that.
Lets create the heroku app.
$ heroku create --stack cedar --buildpack http://github.com/zeebo/buildpack.git
Creating tranquil-refuge-9104... done, stack is cedar
http://tranquil-refuge-9104.herokuapp.com/ | git@heroku.com:tranquil-refuge-9104.git
Git remote heroku added
Add in a free mongo database and configure the DATABASE_URL:
$ heroku addons:add mongolab:starter
-----> Adding mongolab:starter to tranquil-refuge-9104... done, v3 (free)
Welcome to MongoLab.
$ heroku config
BUILDPACK_URL => http://github.com/zeebo/buildpack.git
MONGOLAB_URI => ...snip...
$ heroku config:add DATABASE_URL=...snip...
Adding config vars and restarting app... done, v4
DATABASE_URL => ...snip...
If I was smarter, I would have just used MONGOLAB_URI in the code, but I’m not
so here we are. Finally, we can just push it up and watch the magic:
$ git push heroku master
Counting objects: 24, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (21/21), done.
Writing objects: 100% (24/24), 3.41 KiB, done.
Total 24 (delta 4), reused 0 (delta 0)
-----> Heroku receiving push
-----> Fetching custom buildpack... done
-----> Go app detected
-----> Configuration
GO_VERSION=go1.0.2
BASE=github.com/zeebo/gostbook
+ github.com/zeebo/gostbook
-----> Using Go go1.0.2.linux-amd64
-----> Fetching Go go1.0.2.linux-amd64
-----> Checking for Mercurial and Bazaar
Fetching hg and bzr
..snip...
Successfully installed mercurial
...snip...
Successfully installed bzr
Cleaning up...
-----> Running go get -u -v all
-----> Copying sources into GOPATH/src/github.com/zeebo/gostbook
-----> Running go get -v github.com/zeebo/gostbook
Fetching https://labix.org/v2/mgo?go-get=1
Parsing meta tags from https://labix.org/v2/mgo?go-get=1 (status code 200)
get "labix.org/v2/mgo": found meta tag main.metaImport{Prefix:"labix.org/v2/mgo", VCS:"bzr", RepoRoot:"https://launchpad.net/mgo/v2"} at https://labix.org/v2/mgo?go-get=1
labix.org/v2/mgo (download)
Fetching https://labix.org/v2/mgo/bson?go-get=1
Parsing meta tags from https://labix.org/v2/mgo/bson?go-get=1 (status code 200)
get "labix.org/v2/mgo/bson": found meta tag main.metaImport{Prefix:"labix.org/v2/mgo", VCS:"bzr", RepoRoot:"https://launchpad.net/mgo/v2"} at https://labix.org/v2/mgo/bson?go-get=1
get "labix.org/v2/mgo/bson": verifying non-authoritative meta tag
Fetching https://labix.org/v2/mgo?go-get=1
Parsing meta tags from https://labix.org/v2/mgo?go-get=1 (status code 200)
labix.org/v2/mgo/bson
labix.org/v2/mgo
github.com/zeebo/gostbook
-----> Discovering process types
Procfile declares types -> web
-----> Compiled slug size is 1.4MB
-----> Launching... done, v6
http://tranquil-refuge-9104.herokuapp.com deployed to Heroku
To git@heroku.com:tranquil-refuge-9104.git
* [new branch] master -> master
And we have a nice guestbook at http://tranquil-refuge-9104.herokuapp.com
It seems like the database name is specified by the host in this case. We can’t just go and create whatever database we want. So we have to update the code to grab this information and use it when we’re making queries. The patch to fix it was pretty easy. Just add a global variable and parse the URL to put the database into it.
<figure class="code"><figcaption>commit.diff </figcaption>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
We just rely on the net/url package to parse the url and grab the database out of the path argument. Since the path contains the leading forward slash, we just slice that off. All thats left is a redeploy:
$ git add .
$ git commit -m 'fixes for database'
[master 2b4bf78] fixes for database
2 files changed, 11 insertions(+), 3 deletions(-)
$ git push heroku master
Counting objects: 7, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 493 bytes, done.
Total 4 (delta 3), reused 0 (delta 0)
-----> Heroku receiving push
-----> Fetching custom buildpack... done
-----> Go app detected
-----> Configuration
GO_VERSION=go1.0.2
BASE=github.com/zeebo/gostbook
+ github.com/zeebo/gostbook
-----> Using Go go1.0.2.linux-amd64
-----> Checking for Mercurial and Bazaar
/app/tmp/repo.git/.cache/venv/bin/hg
/app/tmp/repo.git/.cache/venv/bin/bzr
-----> Running go get -u -v all
-----> Copying sources into GOPATH/src/github.com/zeebo/gostbook
-----> Running go get -v github.com/zeebo/gostbook
github.com/zeebo/gostbook
-----> Discovering process types
Procfile declares types -> web
-----> Compiled slug size is 1.4MB
-----> Launching... done, v7
http://tranquil-refuge-9104.herokuapp.com deployed to Heroku
To git@heroku.com:tranquil-refuge-9104.git
52a2171..2b4bf78 master -> master
And to my surprise, it worked on the second try!
I hope this post showed some of what can be done with Go. In little time and code I was able to construct that awesome 1997 guestbook. This just scratched the surface of the cool stuff going on in the Go ecosystem. There’s code competion, sublime text integration, hosted automatically generated documentation, and continuous integration. The Go tool is awesome and able to build the vast majority of Go code that lives anywhere with one command. I highly recommend looking into Go for your next project.




In yesterday's post I threw in the following that I've been asked to clarify:
“we know that those bypass buttons are clicked 60% of the time by Chrome users”
Chrome collects anonymous statistics from users who opt in to such collection (and thank you to those who do!). One of those statistics covers how frequently people bypass SSL interstitials. (As always, the Chrome privacy policy has the details.)
We define bypassing the interstitial as clicking the ‘Proceed anyway’ button and not bypassing as either closing the tab, navigating elsewhere, or clicking the ‘Back’ button.
I picked five days at random over the past six weeks and averaged the percentages of the time that users bypassed rather than not. That came to 61.6%.
There may be some biases here: we may have a biased population because we only include users who have opted in to statistics collection. We are also counting all interstitals: there may be a small number of users who bypass a lot of SSL errors. But that's the data that we have.
(These are my notes from the first half of my talk at HOPE9 last weekend. I write notes like these not as a script, but so that I have at least some words ready in my head when I'm speaking. They are more conversational and less organised than a usual blog post, so please forgive me the rough edges.)
HTTPS tends to cause people to give talks mocking certificate security and the ecosystem around it. Perhaps that's well deserved, but that's not what this talk is about. If you want to have fun at the expense of CAs, dig up one of Moxie's talks. This talk deals with the fact that your HTTPS site, and the sites that you use, probably don't even reach the level where you get to start worrying about certificates.
I'm a transport security person so the model for this talk is that we have two computers talking over a malicious network. We assume that the computers themselves are honest and uncompromised. That might be a stretch in these malware-ridden times, but that's the area of host security and I'm not talking about that today. The network can drop, alter or fabricate packets at will. As a lemma, we also assume that the network can cause the browser to load any URL it wishes. The network can do this by inserting HTML into any HTTP request and we assume that every user makes some unencrypted requests while browsing.
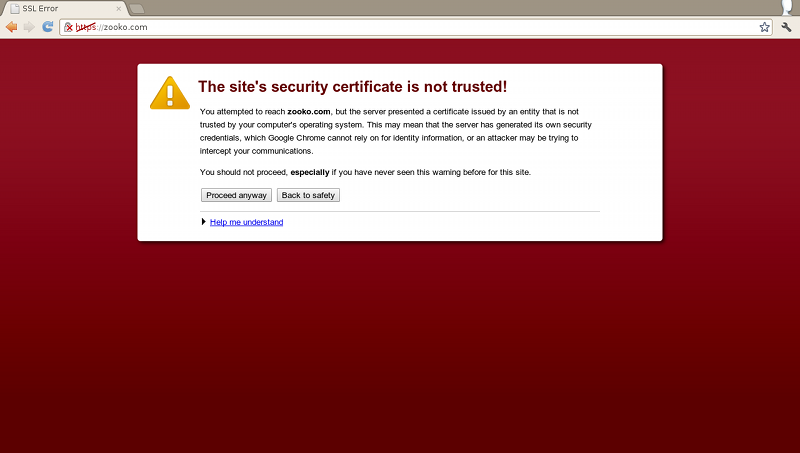
If the average user typed mail.google.com into a browser and saw the following, what fraction of them do you think would login, none the wiser?
Can you even see what's terribly wrong here?
The problem is that the page isn't served over HTTPS. It should have been, but when a user types a hostname into a browser, the default scheme is HTTP. The server may attempt to redirect users to HTTPS, but that redirect is insecure: a MITM attacker can rewrite it and keep the user on HTTP, spoofing the real site the whole time. The attacker can now intercept all the traffic to this perfectly well configured and secure website.
This is called SSL stripping and it's terribly simple and devastatingly effective. We probably don't see it very often because it's not something that corporate proxies need to do, so it's not in off-the-shelf devices. But that respite is unlikely to last very long and maybe it's already over: how would we even know if it was being used?
In order to stop SSL stripping, we need to make HTTPS the only protocol. We can't do that for the whole Internet, but we can do it site-by-site with HTTP Strict Transport Security (HSTS).
HSTS tells browsers to always make requests over HTTPS to HSTS sites. Sites become HSTS either by being built into the browser, or by advertising a header:
Strict-Transport-Security: max-age=8640000; includeSubDomains
The header is in force for the given number of seconds and may also apply to all subdomains. The header must be received over a clean HTTPS connection.
Once the browser knows that a site is HTTPS only, the user typing mail.google.com is safe: the initial request uses HTTPS and there's no hole for an attacker to exploit.
(mail.google.com and a number of other sites are already built into Chrome as HSTS sites so it's not actually possible to access accounts.google.com over HTTP with Chrome - I had to doctor that image! If you want to be included in Chrome's built-in HSTS list, email me.)
HSTS can also protect you, the webmaster, from making silly mistakes. Let's assume that you've told your mother that she should always type https:// before going to her banking site or maybe you setup a bookmark for her. That's honestly more than we can, or should, expect of our users. But let's say that our supererogatory user enters https://www.citibank.com in order to securely connect to her bank. What happens? Well, https://www.citibank.com redirects her to http://www.citibank.com. They've downgraded the user! From there, the HTTP site should redirect back to HTTPS, but the damage has been done. An attacker can get in through the hole.
I'm honestly not picking on Citibank here. They were simply the second site that I tried and I was some surprised that the first site didn't have the problem. It's a very easy mistake to make, and everything just works! It's a completely silent disaster! But HSTS would have either prevented it, or would have failed closed.
HSTS also does something else. It turns this:
Into this:
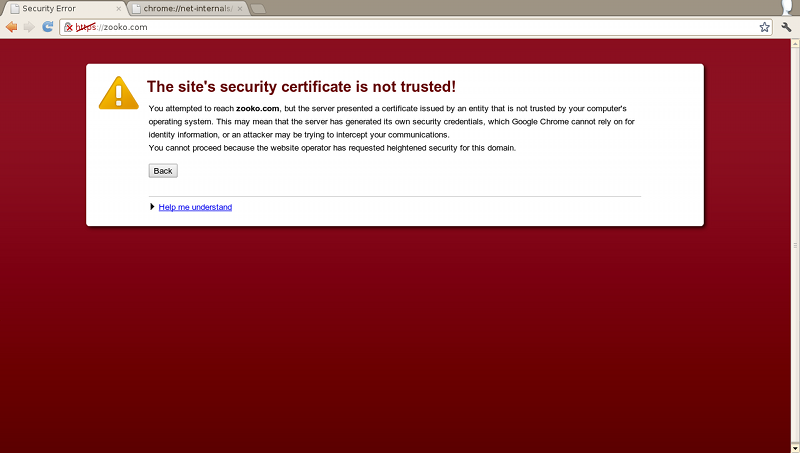
The “bypass this certificate error” button has gone. That button is a UI disaster. Asking regular people to evaluate the validity of X.509 certificates is insane. It's a security cop-out that we're saddled with, and which is causing real damage.
We've seen widespread MITM attacks using invalid certificates in Syria and, in recent weeks, Jordan. These attacks are invalid! This is squarely within our threat model for transport security and it shouldn't have been a risk for anybody. But we know that those bypass buttons are clicked 60% of the time by Chrome users. People are certainly habituated to clicking them and I bet that a large number of people were victims of attacks that we should have been able to prevent.
If you take only one thing away from this talk, HSTS should be it.
One we're sorted HSTS we have another problem. These snippets of HTML are gaping wide holes in your security:
<script src="http://... <link href="http://... <embed src="http://...
It's called mixed scripting and it happens when a secure site loads critical sub-resources over HTTP. It's a subset of mixed content: mixed content covers loading any sub-resource insecurely. Mixed content is bad, but when the resource is Javascript, CSS, or a plugin we give is another name to make it clear that its a lot more damaging.
When you load sub-resources over HTTP, an attacker can replace them with content of their choosing. The attacker also gets to choose any page on your HTTPS site with the problem. That includes pages that you don't expect to be served over HTTPS, but happen to be mapped. If you have this problem anywhere, on any HTTPS page, the attacker wins.
With complex sites, it's very difficult to ensure that this doesn't happen. One good way to limit it is to only serve over HTTPS so that there aren't any pages that you expect to serve over HTTP. Also, HSTS might also save you if you're loading mixed script from the same domain.
Another mitigation is to use scheme-relative URLs everywhere possible. These URLs look like //example.com/bar.js and are valid in all browsers. They inherit the scheme of the parent page, which will be HTTP or HTTPS as needed. (Although it does mean that if you load the page from disk then things will break. The scheme will be file:// in that case.)
Fundamentally this is such an easy mistake to make, and such a problem, that the only long term solution is for browsers to stop loading insecure Javascript, CSS and plugins for HTTPS sites. To their credit, IE9 does this and did it before Chrome. But I'm glad to say that Chrome has caught up and mixed scripting is now blocked by default, although with a user-override:
Yes, there's another of those damm bypass buttons. But we swear that it's just a transitional strategy and it already stops silent exploitation in a hidden iframe.
HTTP and HTTPS cookie jars are the same. No really: cookies aren't scoped to a protocol! That means that if you set a Cookie on https://example.com and then make a request to http://example.com, the cookies will be sent in the clear! In order to prevent this, you should be setting secure on your HTTPS cookies. Sadly this is a very easy thing to miss because everything will still work if you omit it, but without the secure tag, attackers can easily steal your cookies.
It's worth noting that HSTS can protect you from this: by preventing the HTTP request from being sent, the cookies can't be leaked that way, but you'll need to include all subdomains in the HSTS coverage.
There's a second corollary to this: attackers can set your HTTPS cookies to. By causing an request to be sent to http://example.com, they can spoof a reply with cookies that then override any existing cookies. In this fashion, an attacker can log a user in as themselves during their interaction with an HTTPS site. Then, say, emails that they send will be saved in the attacker's out-box.
There's no very good protection against this except HSTS again. By preventing any HTTP requests you can stop the attacker from spoofing a reply to set the cookies. Against, HSTS needs to cover all subdomains in order to be effective against this.
You should go to https://www.ssllabs.com and run their scan against your site. It's very good, but ignore it if it complains about the BEAST attack. It'll do so if you make a CBC ciphersuite your top preference. Browsers have worked around BEAST and non-browser clients are very unlikely to provide the attacker enough access to be able to pull it off. You have a limited amount of resources to address HTTPS issues and I don't think BEAST should make the list.
You should get a real certificate. You probably already have one but, if you don't, then you're just training more people to ignore certificate errors and you can't have HSTS without a real certificate. StartSSL give them away for free. Get one.
If you've reached this far and have done all of the above, congratulations: you're in the top 0.1% of HTTPS sites. If you're getting bored, this is a reasonable point to stop reading: everything else is just bonus points from now on.
You should consider forward secrecy. Forward secrecy means that the keys for a connection aren't stored on disk. You might have limited the amount of information that you log in order to protect the privacy of your users, but if you don't have forward secrecy then your private key is capable of decrypting all past connections. Someone else might be doing the logging for you.
In order to enable forward secrecy you need to have DHE or ECDHE ciphersuites as your top preference. DHE ciphersuites are somewhat expensive if you're terminating lots of SSL connections and you should be aware that your server will probably only allow 1024-bit DHE. I think 1024-bit DHE-RSA is preferable to 2048-bit RSA, but opinions vary. If you're using ECDHE, use P-256.
You also need to be aware of Session Tickets in order to implement forward secrecy correctly. There are two ways to resume a TLS connection: either the server chooses a random number and both sides store the session information, of the server can encrypt the session information with a secret, local key and send that to the client. The former is called Session IDs and the latter is called Session Tickets.
But Session Tickets are transmitted over the wire and so the server's Session Ticket encryption key is capable of decrypting past connections. Most servers will generate a random Session Ticket key at startup unless otherwise configured, but you should check.
I'm not going to take the time to detail how to configure this here. There are lots of webservers and it would take a while. This is more of a pointer so that you can go away and research it if you wish.
(The rest of the talk touched on OpenSSL speed, public key pinning, TLS 1.1 and 1.2 and a few other matters, but I did those bits mostly on the fly and don't have notes for them.)
-compiler option: go build -compiler gccgo myprog. The tools used for calls between Go and C/C++, cgo and SWIG, also support gccgo.


We should have some ways of coupling programs like garden hose--screw in another segment when it becomes necessary to massage data in another way. This is the way of IO also.That is the way of Go also. Go takes that idea and pushes it very far. It is a language of composition and coupling.
The range of abstractions that C++ can express elegantly, flexibly, and at zero costs compared to hand-crafted specialized code has greatly increased.That way of thinking just isn't the way Go operates. Zero cost isn't a goal, at least not zero CPU cost. Go's claim is that minimizing programmer effort is a more important consideration.
I've created a small wrapper for libunbound for use in Go.
The code can be found at github. It depends on my Go DNS library which can be found here.
Official announcement on the Unbound-users@ list.
To give you a little taste of how it looks, I've (re)created tutorials 2 to 6 in Go. Tutorial 2 looks like this, for instance:
package main
// https://www.unbound.net/documentation/libunbound-tutorial-2.html
import (
"dns"
"fmt"
"os"
"unbound"
)
func main() {
u := unbound.New()
defer u.Destroy()
if err := u.ResolvConf("/etc/resolv.conf"); err != nil {
fmt.Printf("error %s\n", err.Error())
os.Exit(1)
}
if err := u.Hosts("/etc/hosts"); err != nil {
fmt.Printf("error %s\n", err.Error())
os.Exit(1)
}
r, err := u.Resolve("www.nlnetlabs.nl.", dns.TypeA, dns.ClassINET)
if err != nil {
fmt.Printf("error %s\n", err.Error())
os.Exit(1)
}
fmt.Printf("%+v\n", r)
}

 Fast forward to today. I found myself trying to understand how to use the Go XML package to unmarshall an XML file into a set of types that I can use. This was spurred by my daughter's recent question of, "Are you still working on our game, Daddy?" So, today I was trying to read a COLLADA (3D model file) and display it into an OpenGL window. My conclusion is that it isn't difficult at all. It was actually easy; so easy, in fact, I felt compelled to write this post afterward. This is a summary of my experience after a couple hours of effort. Keep in mind, a lot of the time was directed towards remembering OpenGL, looking for examples to follow, and figuring out the COLLADA specification. Here we focus on reading the COLLADA file. Understanding the COLLADA File The COLLADA file specification is a pretty extensive XML schema whose full specification can be found here and the summary that actually helped me understand it is found here. In this post, I am focusing on the data I need to get to; which are vertices, normals, and triangles. Here is an example file with only those portions I cared about remaining and the tags of particular interest highlighted in yellow. <?xml version="1.0" encoding="utf-8"?><COLLADA xmlns="http://www.collada.org/2005/11/COLLADASchema" version="1.4.1"> <asset> <contributor> <author>Blender User</author> <authoring_tool>Blender 2.58.0 r37702</authoring_tool> </contributor> <created>2011-07-26T02:34:24</created> <modified>2011-07-26T02:34:24</modified> <unit name="meter" meter="1"/> <up_axis>Z_UP</up_axis> </asset> <library_geometries> <geometry id="Plane-mesh"> <mesh> <source id="Plane-mesh-positions"> <float_array
id="Plane-mesh-positions-array" count="12">1 0.3503274 0 1
-0.3503274 0 -1 -0.9999998 0 -0.9999997 1 0</float_array> </source> <source id="Plane-mesh-normals"> <float_array id="Plane-mesh-normals-array" count="6">0 0 1 0 0 1</float_array> </source> <vertices id="Plane-mesh-vertices"> <input semantic="POSITION" source="#Plane-mesh-positions"/> </vertices> <polylist count="2"> <input semantic="VERTEX" source="#Plane-mesh-vertices" offset="0"/> <input semantic="NORMAL" source="#Plane-mesh-normals" offset="1"/> <vcount>3 3 </vcount> <p>0 0 3 0 1 0 3 1 2 1 1 1</p> </polylist> </mesh> </geometry> </library_geometries></COLLADA>When writing the code to read this file, I made some assumptions about the COLLADA file's data because I was the originator of the file and had control. First, I assumed there was no texture coordinates in the file, this changes how one would parse the <p>0 0 3 0 1 0 3 1 2 1 1 1</p> section from file above (this summary describes the alternate form here).
Second, I assumed the <polylist> is always describing triangles
and not quads. The above assumptions would change for production code
and it is easy enough to get the data that it wouldn't be a problem to
handle more than the single case I handle here.Organizing and Annotating Data Types in Preparation of Unmarshalling the COLLADA File Using Go's XML package to read the file data in couldn't be any easier. You create struct types that represent the tags you care about and 'annotate' fields with metadata that tells the parser how to handle data and where to put it. If you follow the rules properly (found in the XML package documentation), you should have no problem getting the XML package to load the data into your types for you. In this case, there was some post processing required to get the <float_array> and <p> data into arrays of appropriate numeric types. Here are the structures I used: type Collada struct { Id string `xml:"attr"` Version string `xml:"attr"` Library_Geometries LibraryGeometries Library_Visual_Scenes LibraryVisualScenes}type LibraryGeometries struct{ XMLName xml.Name `xml:"library_geometries"` Geometry []Geometry} type Geometry struct{ XMLName xml.Name `xml:"geometry"` Id string `xml:"attr"` Mesh Mesh}type Mesh struct { XMLName xml.Name `xml:"mesh"` Source []Source Polylist Polylist}type Source struct{ XMLName xml.Name `xml:"source"` Id string `xml:"attr"` Float_array FloatArray `xml:"float_array"`}type FloatArray struct{ XMLName xml.Name `xml:"float_array"` Id string `xml:"attr"` CDATA string `xml:"chardata"` Count string `xml:"attr"`}type Polylist struct{ XMLName xml.Name `xml:"polylist"` Id string `xml:"attr"` Count string `xml:"attr"` // List of integers, each specifying the number of vertices for one polygon VCount string `xml:"vcount"` // list of integers that specify the vertex attributes P string `xml:"p"` }type LibraryVisualScenes struct { XMLName xml.Name `xml:"library_visual_scenes"` VisualScene VisualScene}type VisualScene struct{ XMLName xml.Name `xml:"visual_scene"` }I highlighted sections above that were of interest. The Id string `xml:"attr"`
section shows how to inform the XML parser to load an attribute value
into a field. The field name should be exported (first letter
capitalized) and be tagged with the `xml:"attr"` metadata. The XMLName xml.Name `xml:"library_geometries"` section shows how you can identify that a structure is associated with a particular XML element. The Source []Source section represents an array that the XML parser will initialize and fill for you. Finally, the CDATA string `xml:"chardata"`
section depicts how you tell the parser where to put text. In this
case, it loaded it with the string of float numbers found in this
element:<float_array
id="Plane-mesh-positions-array" count="12">1 0.3503274 0 1
-0.3503274 0 -1 -0.9999998 0 -0.9999997 1 0</float_array> Unmarshalling the COLLADA File Oh, I almost forgot. Once you've created your data types, the call to fill your data simply looks like the following: //// Create meshes from COLLADA file// // There are some major limitations for this currently// 1) Must only contain Triangles// 2) No support for animation or materials at the moment// 3) Will not read translations or rotations//func BuildModel(filename string) *data.Model{ file, err := os.Open(filename) if err!= nil{ fmt.Println(err.String()) } c := new(Collada) err = xml.Unmarshal(file, c) if err!= nil{ fmt.Println(err.String()) }In the above code, I've used a filename to open a file and I've constructed the root document element (the Collada type) on this line: c := new(Collada)and called xml.Unmarshall passing the file and a reference to the Collada data type instance. Everything we've properly modeled will be accessible from this root element. Again, I had to do some post-processing to convert some textual numbers to float and int arrays, but in the end, an ugly model I built in Blender like this:  was being shown in a Go COLLADA Model Viewer I built like this:  Again, this was super easy and only took about 2-3 hours (I've been writing this post for about the same amount of time). The next step will be to create and apply textures to the model and see how how to get it displayed in the model viewer. |
We all love transport security but it can get in the way of a good tcpdump. Unencrypted protocols like HTTP, DNS etc can be picked apart for debugging but anything running over SSL can be impenetrable. Of course, that's an advantage too: the end-to-end principle is dead for any common, unencrypted protocol. But we want to have our cake and eat it.
Wireshark (a common tool for dissecting packet dumps) has long had the ability to decrypt some SSL connections given the private key of the server, but the private key isn't always something that you can get hold of, or want to spread around. MITM proxies (like Fiddler) can sit in the middle of a connection and produce plaintext, but they also alter the connection: SPDY, client-certificates etc won't work through them (at least not without special support).
So here's another option: if you get a dev channel release of Chrome and a trunk build of Wireshark you can run Chrome with the environment variable SSLKEYLOGFILE set to, say, /home/foo/keylog. Then, in Wireshark's preferences for SSL, you can tell it about that key log file. As Chrome makes SSL connections, it'll dump an identifier and the connection key to that file and Wireshark can read those and decrypt SSL connections.
The format of the key log file is described here. There's an older format just for RSA ciphersuites that I added when Wireshark decrypted purely based on RSA pre-master secrets. However, that doesn't work with ECDHE ciphersuites (amongst others) so the newer format can be used to decrypt any connection. (You need the trunk build of Wireshark to support the newer format.) Chrome currently writes records of both formats.
This can also be coupled with spdy-shark to dissect SPDY connections.
Since key log support is part of NSS, support will hopefully end up in Firefox in the future.










Now that the API seems to stabilize it is time to update these items.
We want to create a little program that prints out the MX records of domains, like so:
% mx miek.nl
miek.nl. 86400 IN MX 10 elektron.atoom.net.Or
% mx microsoft.com
microsoft.com. 3600 IN MX 10 mail.messaging.microsoft.com.We are using my Go DNS package. First the normal header of a Go program, with a bunch of imports. We need the dns package:
package main
import (
"dns"
"os"
"fmt"
)Next we need to get the local nameserver to use:
config, _ := dns.ClientConfigFromFile("/etc/resolv.conf")Then we create a dns.Client to perform the queries for us. In Go:
c := new(dns.Client)We skip some error handling and assume a zone name is given. So we prepare our question. For that to work, we need:
dns.Msg);dns.Msg.MsgHdr);os.Args[1] contains the zone name.Which translates into:
m := new(dns.Msg)
m.SetQuestion(dns.Fqdn(os.Args[1], dns.TypeMX)
m.MsgHdr.RecursionDesired = trueThen we need to finally 'ask' the question. We do this by calling the Exchange() function.
r, err := c.Exchange(m, config.Servers[0]+":"+config.Port)Check if we got something sane. The following code snippet prints the answer section of the received packet:
if r != nil {
if r.Rcode != dns.RcodeSuccess {
fmt.Printf(" *** invalid answer name %s after MX query for %s\n", os.Args[1], os.Args[1])
os.Exit(1)
}
// Stuff must be in the answer section
for _, a := range r.Answer {
fmt.Printf("%v\n", a)
}
} else {
fmt.Printf("*** error: %s\n", err.String())
}And we are done.
The full source of mx.go can be found over at github. Compiling works with go build.
Last week, I gave a talk about Go at the Boston Google Developers Group meeting. There were some problems with the recording, so I have rerecorded the talk as a screencast and posted it on YouTube.
Here are the answers to questions asked at the end of the talk.
Q. How does Go work with debuggers?
To start, both Go toolchains include debugging information that gdb can read in the final binaries, so basic gdb functionality works on Go programs just as it does on C programs.
We’ve talked for a while about a custom Go debugger, but there isn’t one yet.
Many of the programs we want to debug are live, running programs. The net/http/pprof package provides debugging information like goroutine stacks, memory profiling, and cpu profiling in response to special HTTP requests.
Q. If a goroutine is stuck reading from a channel with no other references, does the goroutine get garbage collected?
No. From the garbage collection point of view, both sides of the channel are represented by the same pointer, so it can’t distinguish the receive and send sides. Even if we could detect this situation, we’ve found that it’s very useful to keep these goroutines around, because the program is probably heading for a deadlock. When a Go program deadlocks, it prints all its goroutine stacks and then exits. If we garbage collected the goroutines as they got stuck, the deadlock handler wouldn’t have anything useful to print except "your entire program has been garbage collected".
Q. Can a C++ program call into Go?
We wrote a tool called cgo so that Go programs can call into C, and we’ve implemented support for Go in SWIG, so that Go programs can call into C++. In those programs, the C or C++ can in turn call back into Go. But we don’t have support for a C or C++ program—one that starts execution in the C or C++ world instead of the Go world—to call into Go.
The hardest part of the cross-language calls is converting between the C calling convention and the Go calling convention, specifically with the regard to the implementation of segmented stacks. But that’s been done and works.
Making the assumption that these mixed-language binaries start in Go has simplified a number of parts of the implementation. I don’t anticipate any technical surprises involved in removing these assumptions. It’s just work.
Q. What are the areas that you specifically are trying to improve the language?
For the most part, I’m not trying to improve the language itself. Part of the effort in preparing Go 1 was to identify what we wanted to improve and do it. Many of the big changes were based on two or three years of experience writing Go programs, and they were changes we’d been putting off because we knew that they’d be disruptive. But now that Go 1 is out, we want to stop changing things and spend another few years using the language as it exists today. At this point we don’t have enough experience with Go 1 to know what really needs improvement.
My Go work is a small amount of fixing bugs in the libraries or in the compiler and a little bit more work trying to improve the performance of what’s already there.
Q. What about talking to databases and web services?
For databases, one of the packages we added in Go 1 is a standard database/sql package. That package defines a standard API for interacting with SQL databases, and then people can implement drivers that connect the API to specific database implementations like SQLite or MySQL or Postgres.
For web services, you’ve seen the support for JSON and XML encodings. Those are typically good enough for ad hoc REST services. I recently wrote a package for connecting to the SmugMug photo hosting API, and there’s one generic call that unmarshals the response into a struct of the appropriate type, using json.Unmarshal. I expect that XML-based web services like SOAP could be framed this way too, but I’m not aware of anyone who’s done that.
Inside Google, of course, we have plenty of services, but they’re based on protocol buffers, so of course there’s a good protocol buffer library for Go.
Q. What about generics? How far off are they?
People have asked us about generics from day 1. The answer has always been, and still is, that it’s something we’ve put a lot of thought into, but we haven’t yet found an approach that we think is a good fit for Go. We’ve talked to people who have been involved in the design of generics in other languages, and they’ve almost universally cautioned us not to rush into something unless we understand it very well and are comfortable with the implications. We don’t want to do something that we’ll be stuck with forever and regret.
Also, speaking for myself, I don’t miss generics when I write Go programs. What’s there, having built-in support for arrays, slices, and maps, seems to work very well.
Finally, we just made this promise about backwards compatibility with the release of Go 1. If we did add some form of generics, my guess is that some of the existing APIs would need to change, which can’t happen until Go 2, which I think is probably years away.
Q. What types of projects does Google use Go for?
Most of the things we use Go for I can’t talk about. One notable exception is that Go is an App Engine language, which we announced at I/O last year. Another is vtocc, a MySQL load balancer used to manage database lookups in YouTube’s core infrastructure.
Q. How does the Plan 9 toolchain differ from other compilers?
It’s a completely incompatible toolchain in every way. The main difference is that object files don’t contain machine code in the sense of having the actual instruction bytes that will be used in the final binary. Instead they contain a custom encoding of the assembly listings, and the linker is in charge of turning those into actual machine instructions. This means that the assembler, C compiler, and Go compiler don’t all duplicate this logic. The main change for Go is the support for segmented stacks.
I should add that we love the fact that we have two completely different compilers, because it keeps us honest about really implementing the spec.
Q. What are segmented stacks?
One of the problems in threaded C programs is deciding how big a stack each thread should have. If the stack is too small, then the thread might run out of stack and cause a crash or silent memory corruption, and if the stack is too big, then you’re wasting memory. In Go, each goroutine starts with a small stack, typically 4 kB, and then each function checks if it is about to run out of stack and if so allocates a new stack segment that gets recycled once it’s not needed anymore.
Gccgo supports segmented stacks, but it requires support added recently to the new GNU linker, gold, and that support is only implemented for x86-32 and x86-64.
Segmented stacks are something that lots of people have done before in experimental or research systems, but they have never made it into the C toolchains.
Q. What is the overhead of segmented stacks?
It’s a few instructions per function call. It’s been a long time since I tried to measure the precise overhead, but in most programs I expect it to be not more than 1-2%. There are definitely things we could do to try to reduce that, but it hasn’t been a concern.
Q. Do goroutine stacks adapt in size?
The initial stack allocated for a goroutine does not adapt. It’s always 4k right now. It has been other values in the past but always a constant. One of the things I’d like to do is to look at what the goroutine will be running and adjust the stack accordingly, but I haven’t.
Q. Are there any short-term plans for dynamic loading of modules?
No. I don’t think there are any technical surprises, but assuming that everything is statically linked simplified some of the implementation. Like with calling Go from C++ programs, I believe it’s just work.
Gccgo might be closer to support for this, but I don’t believe that it supports dynamic loading right now either.
Q. How much does the language spec say about reflection?
The spec is intentionally vague about reflection, but package reflect’s API is definitely part of the Go 1 definition. Any conforming implementation would need to implement that API. In fact, gc and gccgo do have different implementations of that package reflect API, but then the packages that use reflect like fmt and json can be shared.
Q. Do you have a release schedule?
We don’t have any fixed release schedule. We’re not keeping things secret, but we’re also not making commitments to specific timelines.
Go 1 was in progress publicly for months, and if you watched you could see the bug count go down and the release candidates announced, and so on.
Right now we’re trying to slow down. We want people to write things using Go, which means we need to make it a stable foundation to build on. Go 1.0.1, the first bug release, was released four weeks after Go 1, and Go 1.0.2 was seven weeks after Go 1.0.1.
Q. Where do you see Go in five years? What languages will it replace?
I hope that it will still be at golang.org, that the Go project will still be thriving and relevant. We built it to write the kinds of programs we’ve been writing in C++, Java, and Python, but we’re not trying to go head-to-head with those languages. Each of those has definite strengths that make them the right choice for certain situations. We think that there are plenty of situations, though, where Go is a better choice.
If Go doesn’t work out, and for some reason in five years we’re programming in something else, I hope the something else would have the features I talked about, specifically the Go way of doing interfaces and the Go way of handling concurrency.
If Go fails but some other language with those two features has taken over the programming landscape, if we can move the computing world to a language with those two features, then I’d be sad about Go but happy to have gotten to that situation.
Q. What are the limits to scalability with building a system with many goroutines?
The primary limit is the memory for the goroutines. Each goroutine starts with a 4kB stack and a little more per-goroutine data, so the overhead is between 4kB and 5kB. That means on this laptop I can easily run 100,000 goroutines, in 500 MB of memory, but a million goroutines is probably too much.
For a lot of simple goroutines, the 4 kB stack is probably more than necessary. If we worked on getting that down we might be able to handle even more goroutines. But remember that this is in contrast to C threads, where 64 kB is a tiny stack and 1-4MB is more common.
Q. How would you build a traditional barrier using channels?
It’s important to note that channels don’t attempt to be a concurrency Swiss army knife. Sometimes you do need other concepts, and the standard sync package has some helpers. I’d probably use a sync.WaitGroup.
If I had to use channels, I would do it like in the web crawler example, with a channel that all the goroutines write to, and a coordinator that knows how many responses it expects.
Q. What is an example of the kind of application you’re working on performance for? How will you beat C++?
I haven’t been focusing on specific applications. Go is still young enough that if you run some microbenchmarks you can usually find something to optimize. For example, I just sped up floating point computation by about 25% a few weeks ago. I’m also working on more sophisticated analyses for things like escape analysis and bounds check elimination, which address problems that are unique to Go, or at least not problems that C++ faces.
Our goal is definitely not to beat C++ on performance. The goal for Go is to be near C++ in terms of performance but at the same time be a much more productive environment and language, so that you’d rather program in Go.
Q. What are the security features of Go?
Go is a type-safe and memory-safe language. There are no dangling pointers, no pointer arithmetic, no use-after-free errors, and so on.
You can break the rules by importing package unsafe, which gives you a special type unsafe.Pointer. You can convert any pointer or integer to an unsafe.Pointer and back. That’s the escape hatch, which you need sometimes, like for extracting the bits of a float64 as a uint64. But putting it in its own package means that unsafe code is explicitly marked as unsafe. If your program breaks in a strange way, you know where to look.
Isolating this power also means that you can restrict it. On App Engine you can’t import package unsafe in the code you upload for your app.
I should point out that the current Go implementation does have data races, but they are not fundamental to the language. It would be possible to eliminate the races at some cost in efficiency, and for now we’ve decided not to do that. There are also tools such as Thread Sanitizer that help find these kinds of data races in Go programs.
Q. What language do you think Go is trying to displace?
I don’t think of Go that way. We were writing C++ code before we did Go, so we definitely wanted not to write C++ code anymore. But we’re not trying to displace all C++ code, or all Python code, or all Java code, except maybe in our own day-to-day work.
One of the surprises for me has been the variety of languages that new Go programmers used to use. When we launched, we were trying to explain Go to C++ programmers, but many of the programmers Go has attracted have come from more dynamic languages like Python or Ruby.
Q. How does Go make it possible to use multiple cores?
Go lets you tell the runtime how many operating system threads to use for executing goroutines, and then it muxes the goroutines onto those threads. So if you’ve written a program that has four or more goroutines executing simultaneously, you can tell the runtime to use four OS threads and then you’re running on four cores.
We’ve been pleasantly surprised by how easy people find it to write these kinds of programs. People who have not written parallel or concurrent programs before write concurrent Go programs using channels that can take advantage of multiple cores, and they enjoy the experience. That’s more than you can usually say for C threads. Joe Armstrong, one of the creators of Erlang, makes the point that thinking about concurrency in terms of communication might be more natural for people, since communication is something we’ve done for a long time. I agree.
Q. How does the muxing of goroutines work?
It’s not very smart. It’s the simplest thing that isn’t completely stupid: all the scheduling operations are O(1), and so on, but there’s a shared run queue that the various threads pull from. There’s no affinity between goroutines and threads, there’s no attempt to make sophisticated scheduling decisions, and there’s not even preemption.
The goroutine scheduler was the first thing I wrote when I started working on Go, even before I was working full time on it, so it’s just about four years old. It has served us surprisingly well, but we’ll probably want to replace it in the next year or so. We’ve been having some discussions recently about what we’d want to try in a new scheduler.
Q. Is there any plan to bootstrap Go in Go, to write the Go compiler in Go?
There’s no immediate plan. Go does ship with a Go program parser written in Go, so the first piece is already done, and there’s an experimental type checker in the works, but those are mainly for writing program analysis tools. I think that Go would be a great language to write a compiler in, but there’s no immediate plan. The current compiler, written in C, works well.
I’ve worked on bootstrapped languages in the past, and I found that bootstrapping is not necessarily a good fit for languages that are changing frequently. It reminded me of climbing a cliff and screwing hooks into the cliff once in a while to catch you if you fall. Once or twice I got into situations where I had identified a bug in the compiler, but then trying to write the code to fix the bug tickled the bug, so it couldn’t be compiled. And then you have to think hard about how to write the fix in a way that avoids the bug, or else go back through your version control history to find a way to replay history without introducing the bug. It’s not fun.
The fact that Go wasn’t written in itself also made it much easier to make significant language changes. Before the initial release we went through a handful of wholesale syntax upheavals, and I’m glad we didn’t have to worry about how we were going to rebootstrap the compiler or ensure some kind of backwards compatibility during those changes.
Finally, I hope you’ve read Ken Thompson’s Turing Award lecture, Reflections on Trusting Trust. When we were planning the initial open source release, we liked to joke that no one in their right mind would accept a bootstrapped compiler binary written by Ken.
Q. What does Go do to compile efficiently at scale?
This is something that we talked about a lot in early talks about Go. The main thing is that it cuts off transitive dependencies when compiling a single module. In most languages, if package A imports B, and package B imports C, then the compilation of A reads not just the compiled form of B but also the compiled form of C. In large systems, this gets out of hand quickly. For example, in C++ on my Mac, including <iostream> reads 25,326 lines from 131 files. (C and C++ headers aren't “compiled form,” but the problem is the same.) Go promises that each import reads a single compiled package file. If you need to know something about other packages to understand that package’s API, then the compiled file includes the extra information you need, but only that.
Of course, if you are building from scratch and package A imports B which imports C, then of course C has to be compiled first, and then B, and then A. The import point is that when you go to compile A, you don’t reload C’s object file. In a real program, the dependencies are usually not a chain like this. We might have A1, A2, A3, and so on all importing B. It’s a significant win if none of them need to reread C.
Q. How do you identify a good project for Go?
I think a good project for Go is one that you’re excited about writing in Go. Go really is a general purpose programming language, and except for the compiler work, it’s the only language I’ve written significant programs in for the past four years.
Most of the people I know who are using Go are using it for networked servers, where the concurrency features have something contribute, but it’s great for other contexts too. I’ve used it to write a simple mail reader, file system implementations to read old disks, and a variety of other unnetworked programs.
Q. What is the current and future IDE support for Go?
I’m not an IDE user in the modern sense, so really I don’t know. We think that it would be possible to write a really nice IDE specifically for Go, but it’s not something we’ve had time to explore. The Go distribution has a misc directory that contains basic Go support for common editors, and there is a Goclipse project to write an Eclipse-based IDE, but I don’t know much about those.
The development environment I use, acme, is great for writing Go code, but not because of any custom Go support.
If you have more questions, please consult these resources.
TLS is the protocol behind most secure connections on the Internet and most TLS is TLS 1.0, despite that fact that the RFC for 1.0 was published in January 1999, over 13 years ago.
Since then there have a two newer versions of TLS: 1.1 (2006) and 1.2 (2008). TLS 1.1 added an explicit IV for CBC mode ciphers as a response to CBC weaknesses that eventually turned into the BEAST attack. TLS 1.2 changes the previous MD5/SHA1 combination hash to use SHA256 and introduces AEAD ciphers like AES-GCM.
However, neither of these versions saw any significant adoption for a long time because TLS's extension mechanism allowed 1.0 to adapt to new needs.
But things are starting to change:
In the long run, getting to 1.2 is worthwhile. The MD5/SHA1 hash combination used previous versions was hoped to be more secure than either hash function alone, but [1] suggests that it's probably only as secure as SHA1. Also, the GCM cipher modes allow AES to be used without the problems (and space overhead) of CBC mode. GCM is hardware accelerated in recent Intel and AMD chips along with AES itself.
But there are always realities to contend with I'm afraid:
Firstly, there's the usual problem of buggy servers. TLS has a version negotiation mechanism, but some servers will fail if a client indicates that it supports the newer TLS versions. (Last year, Yngve Pettersen suggested that 2% of HTTPS servers failed if the client indicated TLS 1.1 and 3% for TLS 1.2.)
Because of this Chrome implements a fallback from TLS 1.1 to TLS 1.0 if the server sends a TLS error. (And we have a fallback from TLS 1.0 to SSL 3.0 if we get another TLS error on the second try.) This, sadly, means that supporting TLS 1.1 cannot bring any security benefits because an attacker can cause us to fallback. Thankfully, the major security benefit of TLS 1.1, the explicit CBC IVs, was retrofitted to previous versions in the form of 1/n-1 record splitting after the BEAST demonstration.
Since these fallbacks can be a security concern (especially the fallback to SSLv3, which eliminates ECDHE forward secrecy) I fear that it's necessary to add a second, redundant version negotiation mechanism to the protocol. It's an idea which has been floated before and I raised it again recently.
But buggy servers are something that we've known about for many years. Deploying new TLS versions has introduced a new problem: buggy networks.
Appallingly it appears that there are several types of network device that manage to break when confronted with new TLS versions. There are some that break any attempt to offer TLS 1.1 or 1.2, and some that break any connections that negotiate these versions. These failures, so far, manifest in the form of TCP resets, which isn't currently a trigger for Chrome to fallback. Although we may be forced to add it.
Chrome dev or iOS users suffering from the first type of device see all of their HTTPS connections fail. Users suffering the second type only see failures when connecting to sites that support TLS 1.1 or 1.2. (Which includes Google.). iOS leaves it up to the application to implement fallback if they wish and adding TLS 1.2 support to Google's servers has caused some problems because of these bad networks.
We're working to track down the vendors with issues at the moment and to make sure that updates are available, and that they inform their customers of this. I'm very interested in any cases where Chrome 21 suddenly caused all or some HTTPS connections to fail with ERR_CONNECTION_RESET. If you hit this, please let me know (agl at chromium dot org).
([1] Antoine Joux, Multicollisions in Iterated Hash Functions: Application to Cascaded Constructions, CRYPTO (Matthew K. Franklin, ed.), Lecture Notes in Computer Science, vol. 3152, Springer, 2004, pp. 306–316.)
After a weekend of hacking on my chess engine weak, I’ve taken it from handling only king and pawn moves to being able to handle moves for all pieces, and over the past couple of days I have also added castling. Major props to the absolutely amazing chess programming wiki which has been an invaluable source throughout.
Next, I need to add pawn promotion and catch up on technical debt - the code is a little messy, and there is a backlog of unit tests to improve.
After that there comes the hairier chess rules, and then, finally, we come on to the interesting stuff - getting the damn thing play well (it’s already beaten me, but that doesn’t say much :-)
This long bank holiday weekend I am planning to hack on my chess engine, weak, and take it from its current rather incomplete state where it can play some king and pawn moves to a place where it can actually play a game of chess (albeit without rules like en passant, threefold repetition, and the like).
Once I am done I plan to write a blog post discussing its implementation and the realm of computer chess engines in general.
I am also currently working on a rather large Go blog post which is ballooning into a lot more work than expected, hence the succinctness of this post :-)
|
A recent post on the golang-nuts mailing list mentioned that Nginx can upgrade on the fly without ever stopping listening to it’s listen socket. The trick is to unset close-on-exec on the listen socket, then fork/exec a new copy of the server (on the upgraded binary) with an argument to tell it to use the inherited file descriptor instead of calling socket() and listen(s).
I wanted to see if I could achieve the same thing with Go, and what changes would be necessary to the standard libraries to make this possible. I got it working, without changing the standard library, so I wanted to explain what I did here.
The code for this post is here.
There are several interesting things I’d like to point out in this program. Twice, I used the pattern of “implement an interface in order to intercept method calls”. This is an important pattern in Go that I don’t think is widely understood and documented.
When I started thinking about this job I knew one of my problems would be to dig down inside of http.(*Server).Serve in order to get it to stop calling Accept() when the old server should shutdown gracefully. The problem is that there’s no hooks in there; the only way out of the loop (“accept, start go routine to process, do it again”) is for Accept to return an error. But if you think of Accept as a system call, you might think, “I can’t get in there and inject an error”. But Accept() is not a system call: it’s a method in the interface net.Listener. Which means that if you make your own object which satisfies net.Listener, you can pass that in to http.(*Server).Serve and do what you want in Accept().
The first time I read about embedding types in structures I got lost and confused. And when I tried it, I had pointers in the mix and I had lots of unexplained nil pointer errors. This time, I read it again and it made sense. Type embedding is essential when you want to interpose one of the methods of an interface. It lets you inherit all the implementations of the underlying object except for the one that you redefine. Take a look at stoppableListener in upgradable.go. The net.Listener interface requires three methods including Accept, Close, and Addr. But I only defined one of those, Accept(). How is it that stoppableListener still implements net.Listener? Because the other two methods “show through” from where they were embedded in it. Only Accept() has a more precise definition. When I wrote Accept(), then I needed to figure out how to talk to the underlying object, in order to pass on the Accept() call. The trick here is to understand that embedding a type creates a new field in your structure with the unqualified name of the type. So I can refer to the net.Listener inside of stoppableListener sl as sl.Listener, and I can call the underlying Accept() as sl.Listener.Accept().
Next I started wondering how to handle the “stopped” error code from Serve(). Immediately exiting with os.Exit(0) isn’t right, because there can still be go routines servicing HTTP clients. We need some way to know when each client is done. Interposition to the rescue again, since we can wrap up the net.Conn returned by Accept() and use it to decrement a count of the number of currently running connections. This technique of interposing the net.Conn object could have other interesting uses. For example, by trapping the Read() or Write() calls, you could enforce rate limiting on the connection, without needing the protocol implementation to know anything about it. You could even do other zany things like implement opportunistic encryption, again without the protocol knowing it was happening.
Once I knew that I would be able to stop my server gracefully, I needed to figure out how to start the new one on the correct file descriptor. Rog Peppe pointed me to the net.FileListener object, which one can construct from an *os.File (which you can make from a raw file descriptor in an int using os.NewFile).
The final problem is that net always sets the close-on-exec flag on file descriptors for sockets it opens. So I needed to turn that off on the listen socket, so that the file descriptor would still be valid in the new process. Unfortunately syscall.CloseOnExec does not take a boolean to tell it what you want (do close or don’t close). So instead, I pulled out the stuff from syscall that I needed and put it directly in upgradable.go. Not pretty, but nicer than hacking the standard library. (This is a nice thing about Go: there’s almost always a way to do what you want, even if you have to hack around just a bit.)
I tested that it works manually (using command-line GETs from another window). I also tested it under load using http_load. It is really cool to be able to set up a load test for 20 seconds and get 3937 fetches/sec, then do the test again, adding in a few “GET http://localhost:8000/upgrade” from another window and still getting 3880 fetches/sec, even as I replaced the running binary a few times during the load test!

Before I get stuck into this post, I want to quickly mention my last. It got to the front page of Hacker News and stayed there for around a day. I submitted it on a whim and did not expect it to get even the slightest bit of attention. Thank you everybody who upvoted it, I am amazed and humbled that people found it (at least somewhat) interesting.
I fully intend to investigate the issue further and to write a follow up. There were some great comments on the Hacker News thread and on the article itself - leads for further research.
I also want to make it clear that the items listed on my upcoming post are coming, however the posts on that list require a fair bit of work and I want to make sure they’re as good as I want them to be. In order to stick to my promised post/week I need to ‘buffer’ a number of meatier posts, meanwhile I am going to throw out ideas I’ve wanted to express for some time.
The subject of today’s post is one of these things I’ve wanted to write about for a while and by coincidence there was a recent HN furore regarding Jeff Atwood’s latest blog post - Please Don’t Learn to Code - which addresses related issues, so I was motivated to write this now. I will try to pull the threads together.
Growing up I spent a lot of time playing around with BASIC on my ZX Spectrum, and more than anything got a massive kick out of seeing this stuff actually do something, actually working on my computer. It was so satisfying.
Ever since, it has been that kick of seeing something actually come together, actually doing something which has driven my interest in computing. It might sound petty, but this thrill has never quite left me, and I really do think it lies at the heart of the pleasure of the thing. To quote edw519:-
The best part is getting something working for the first time where nothing was there before. For me, this is so exciting that I still I do a “happy dance” every time.
One utterly delightful aspect of programming is how low the barriers are to building things. If you wanted to design and build a car, say, you’d need lots of money and lots of people and a funnelling process from idea to physical reality to achieve your dreams, with plenty of difficult compromises in between. You’d certainly find it incredibly challenging not to mention expensive to try this on your own, to the extent it would be rather mad to try it at all.
Compare this to programming - all you need is a computer - even an ultra-cheap laptop is sufficient, and that combined with the web and all the free material out there is enough to get you from any level to really rather proficient limited only by your attitude and hard work. I can think of nothing else quite like it.
Fred Brooks put it far more eloquently than I ever could:-
The programmer, like the poet, works only slightly removed from pure thought-stuff. He builds castles in the air, from air, creating by exertion of the imagination. … Yet the program construct, unlike the poet’s words, is real in the sense that it moves and works, producing visible outputs separate from the construct itself. … The magic of myth and legend has come true in our time. One types the correct incantation on a keyboard, and a display screen comes to life, showing things that never were nor could be.
Solving abstract problems with few constraints while still actually having an impact on the real world is a large part of the appeal of programming. It’s important not to forget what a miracle this stuff is - we build things which ‘exist’ in what amounts to an imaginary world of electrons travelling around lumps of transmuted sand which somehow do things which people find useful, so useful in fact, that these ghosts in the machine have utterly revolutionised the world and continue to do so at an ever increasing rate.
It is my strong conviction that talent and intelligence are the smallest components of the make up of a good programmer. I do believe they make a difference, but are important to a lesser degree than many think.
You need to be able to think logically and be capable of keeping a certain degree of state in your mind, that’s the talent of it, and you need to be bright enough to explore a problem sufficiently to find a solution, which is where the intelligence lies. But these are only pre-requisites. If you have enough of both, then you are going to be able to program (it turns out that a surprising number of people cannot, though to what degree that is talent vs. attitude I dont know.)
Attitude is the really crucial component. The vast size of the subject matter and the vast complexity of the machine in front of you means hubris is the biggest error you can possibly make. You will make mistakes, do stupid things, and misunderstand what the computer is actually doing much of the time. The vital attitude to have in facing this reality is to remain humble. As Dijkstra put it:-
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague.
A programmer who lacks this humility can be absolutely nightmarish to deal with. Mistakes get brushed under the carpet, code remains an awful unmaintainable mess because ‘it works’ and that’s sufficient (that whole subject is likely to be an entire other ranty post), and things never improve because the first step in improving something is to admit that there’s something which needs improving. You can’t suck less every year without admitted you suck in the first place.
The other, slightly less important, but still critical component of being a good programmer is hard work. Things are always harder than they seem. Any non-trivial problem you’re dealing with will screw you over repeatedly before you solve it, and not until you’ve felt like giving up 3 times will it finally decide to behave. Oh, and the final 10% of the project will take 90% of the time. You just have to keep on going.
This latter point is in fact a lesson I’ve had to learn the hard way with personal projects. I have started several highly ambitious projects, only to hit problems early and give up (‘hey this is meant to be a hobby, this is no fun!’, etc.) - my chess engine project, weak, may be progressing slowly, but it is progressing and I refuse to give up on it.
Another skill which matters rather a lot is the ability to communicate. If you can’t communicate your great idea or the fatal technical flaw in a proposed plan, then no matter how able you are as a developer your voice just won’t be heard. Also, if you can’t communicate well it’s a lot easier to end up in realms of unpleasantness with others, which gets in the way of everything.
Back to the furore. I strongly believe that programming should be open for all, and new programmers welcomed with open arms. This thing is amazing and nobody has the right to tell anybody that they can’t choose to learn this craft and get that wonderful kick out of making computers actually do stuff. The fact that there has been a big movement to spread coding knowledge is great, the more the merrier I say.
Having said that, I think Jeff has hit on an inconvenient and slightly unpalatable truth which strongly links back to the two crucial characteristics of a good programmer. What we emphatically don’t need are new programmers who believe programming is incredibly easy yet wonder why their spaghetti monster runs so slowly, or managers who learn to write a very simple rails app and therefore get to treat you with less respect because it’s ‘all so easy’. Most of all, we don’t need people thinking developers are fungible commodities, because that simply ain’t so.
What’s needed is humility, commitment, and an understanding that it takes many years to become truly proficient at this craft.
Another uncomfortable truth is that we professional programmers often feel threatened by the idea that all these young whippersnappers might come in and make us look incredibly stupid and redundant. The nightmare scenario of an inexperienced guy coming in and doing in 1 week what took you 4 months is not a pleasant thought.
The solution is to not attach your identity1 too closely to your code. You are not your job. Personally I’ve found this a very hard lesson and it’s something I still struggle with2, but forming this separation is so clearly the answer that it’s worth the struggle.
Try to be the best programmer you can be. Focus on creating solutions to people’s problems because that’s ultimately what matters, but don’t forget that maintainability matters too and code quality informs a lot of the externally observable quality of your solution.
Have fun. Build stuff you’re proud of. And above all else, be nice to other people who are also trying to improve themselves. I know I fail at that often enough myself, and it can sometimes be incredibly difficult, but ultimately we are all idiots, so the best we can do is to try and help each other be a little less stupid.
I reference this post in order to give credit where it’s due. I want to make it clear that I actually strongly dislike the tone of Zed Shaw’s blog post, not to mention many other occasions where he’s, in my opinion, acted in rather a bullying fashion (e.g. this and of course this). He is a great programmer, and his books are equally brilliant, but his behaviour towards others is not.
As I commented on hacker news, my perception of that kind of bullying nastiness put me off working on anything public for a long while. I take responsibility for my lack of productivity, but that kind of attitude certainly didn’t help anything. I don’t think it helps anybody.
I don’t want to be too much of a pop psychologist, but I do wonder whether the stereotypical experience of feeling somewhat inadequate at school while finding a means of gaining a sense of value via programming/working with computers binds self worth to your work early on. Of course, this is by no means the experience of all programmers out there, but I do think it is the experience of a fair few, including myself.


In this post I explore what I perceive to be a fundamental issue with object orientation via a type hierarchy.
I want to make it clear that this post is emphatically not an attack on C# (a language I admire1), nor is C# the only language to implement type hierarchies (java is a better-known language which takes this approach), rather it’s a criticism of a general trait of the kind of object orientation implemented2 by languages like C#, which due to my familiarity with it is the language I use in this post to explore my point.
When you write a program using a C#-like language you typically start by modelling your problem as a hierarchical set of classes which represent your domain. You then procede to ‘flesh out’ and expand upon these types with code which actually implements your program.
After a while you inevitably find an exception to the rules of the system you have created - your types turn out not to match the problem in some way. Typically this occurs later after a lot of work has already been done which is now strongly tied to the structure of your type hierarchy, so you are left with a problem - do you hack around the incongruity, usually the quickest solution, or restructure your types to adapt to the new requirement?
If you choose the former your hierarchy not only fails represent the problem anymore, it actively misleads you about it. If you choose the latter, you end up spending a long time yak shaving - working on something which has absolutely nothing to do with the problem itself and is purely a product of the system in which you are writing your program - the very definition of accidental complexity.
To explore this problem more concretely, let’s take a look at an actual example.
Note that, whatever example I choose, it’s inevitable that it will not fully capture this problem the way architecting a big project under deadline pressure will. However, exploring actual code is of such value that I think it worth doing regardless.
That said, let’s consider a type hierarchy which represents trades made on financial exchanges:-
class Exchange {
public string Bic { get; set; }
public string Name { get; set; }
}
abstract class Security {
public string Description { get; set; }
public Exchange Exchange { get; set; }
public string Isin { get; set; }
}
class Stock : Security {
}
class Bond : Security {
public DateTime Expiry { get; set; }
}
class Trade {
public decimal Price { get; set; }
public decimal Quantity { get; set; }
public Security Security { get; set; }
}
So far, so good - this seems like a sensible approach and so we go ahead and write a lot of code around this hierarchy.
The code gradually becomes deeply coupled to our type design - we expect all financial securities to possess an ISIN (an international identification number), a description and an exchange which itself possesses a name and a BIC (bank identification code), we expect stocks to possess no extra properties, bonds to possess expiry dates, and trades to possess a security, price and quantity. The client is happy, the system works well and your code is nice and clean.
Suddenly the client demands a change - they are about to trade options and need to bring them into the system. Fine you think, so you come up with a class:-
class Option : Security {
public bool Call { get; set; }
public decimal LotSize { get; set; }
public DateTime Maturity { get; set; }
public decimal StrikePrice { get; set; }
}
But a problem arises - options are typically not assigned ISINs, and now we have a property which is meaningless for options. We are faced with the dilemma - a lot of the code is now reliant on Isin, and NullReferenceExceptions are getting thrown all over the place because the field isn’t getting populated. Do we remove the Isin field from Security and create a separate classification between physical and derivative securities (or perhaps ISIN-possessing instruments and non-ISIN-possessing instruments) - one containing Isin and one not? Or do we find some other, less salubrious way around the problem?
The client is getting angry now - there’s a hold up, developers are arguing about what to do, and the trading systems needs to be in place by the next day or some P45s are going to be handed out. So it’s decided - quick-fix now, real fix later:-
// Lots of:-
if(security.Isin == null) {
...
}
// Not to mention:-
if(security is Option) {
...
} else {
...
}
// And maybe even some:-
switch(security.GetType().Name) {
case "Option":
...
case "Stock":
...
...
}
Our code is suddenly not looking so great. Our type hierarchy now falsely implies that all securities have ISINs, a particular issue for developers new to the project, we have hacks all over the place, maybe not enough (we’re fairly sure we got everything but there are always those nooks and crannies which slip through the test suite), we are forced to add new hacks as we go and confidence in our code is definitely eroded.
Suddenly a new requirement arises - it turns out securities need to refer to traded exchange which might be different for two otherwise identical securities, but our architecture has lumped exchange with securities. We are back to our dilemma again…
Again, I emphasise that the above example is necessarily imperfect, as to practically fit an example of this problem into a blog post necessitates quite some trivialising. That being said, hopefully it makes the point a little more concrete.
An objection here might be that these change requests merely exposed design mistakes made early on in the project whose impact inevitably got magnified down the line as code was written on the assumption that these mistakes were in fact valid. The problem with that argument is to me the problem with the waterfall method for software development - it assumes you know a great deal up front, something which is very rarely the case.
The reality of software development is almost the opposite of that assumed by approaches which require large amounts of upfront structural foundations to be laid. Requirements and facts around your code tends to change constantly and often in utterly unexpected ways, so having a structure up front which lays down brittle laws about your system is setting yourself up to fail.
The brittleness of the laws is the real issue - if their failing didn’t result in hacks or yaks then there wouldn’t be as much of a problem.
I hate to state a problem without suggesting solutions, I am after all a programmer, and our job is to solve problems, not just create them.
I am certainly not suggesting that object orientation is somehow fundamentally flawed, nor am I advocating writing code procedurally when it could benefit from the encapsulation, abstraction and de-duplication of an alternative approach purely out of FUD about potential future issues, rather I think that if you are going to write in a language which supports this approach it’s important to consider this issue before committing to representing your problem this way.
Some ideas:-
There are methods and patterns for separation of concerns and decoupling of related code, including techniques like dependency injection, which may help mitigate this problem to some degree while still using a C#-like language.
Functional programming is enjoying a great upswing in interest and popularity these days. I wonder whether the stronger type systems of these languages and the greater guarantees about what a function does/does not do (i.e. less likely to produce side-effects, immutable state) might provide a means to more quickly adapt a change to the model at compile- rather than run-time.
Bottom-up programming in a language like Lisp offers an enormous amount of flexibility in meta-programming and might make downstream changes easier to introduce later in the development process.
Dynamic programming languages like Python, Ruby and Lisp provide a far less rigid type structure - types don’t necessarily need to be known at compile time, meaning you have a great deal of flexibility to write functions which are less tied to a previously-determined structure than in a statically-typed language.
Go provides an intriguingly simplified version of static typing where no type hierarchy is permitted to be defined at all, rather you express relations between types through implicit interfaces which define types through what they do rather than what they are. They are implicit in that as soon as you’ve defined what you want, i.e. what methods a type possesses, then any type which possesses those methods implements the interface.
Smalltalk implements object orientation in quite a different fashion from C#-like languages, with emphasis on passing messages between objects rather than the structure of the classes themselves. This could help reduce the dependency on initial structural decisions.
(ECMA|Java)script allows you to define relations between objects based on object prototypes rather than static classes, you simply can’t declare static user-defined types at all.
I don’t want to advocate a particular solution above any other, as I am still undecided and exploring these ideas myself, not to mention the fact that a lot of this stuff sits decidedly in the grey area of rather subjective choices where it’s hard to definitely prove one approach is better than another.
I do however think that the brittleness of the upfront type hierarchy is a real issue which needs to be carefully considered before writing a large program and weighed up against other engineering approaches.
I have spent several years working with C#. Overall it’s a fantastic language which has grown ever more fantastic over time. Starting as, frankly, Microsoft Java, it has grown to incorporate generics, better support for functional style programming through a neat lambda syntax, libraries offering standard functional-style methods such as map, filter and fold (select, where and aggregate respectively in C# parlance), a declarative syntax for querying generic collections via LINQ as well as numerous other little features which make it a very nice language to work with. It’s well-engineered and surprisingly ambitious.
I say this, rather than just saying ‘I have a problem with object orientation’, as there are different interpretations as to how object orientation should be implemented, and a C#-ish implementation is just one approach - cf. smalltalk.
Goプログラミング言語仕様の翻訳を最新にアップデートしました。
細かい更新箇所は多いのですが、前回の翻訳からの変更点は以下です。
※2012/5/9 タイプミスを修正しました。報告いただきありがとうございました。

Okay, so I haven’t updated this blog in quite some time.
I don’t want to become one of those people whose blog consists of very few blog posts, mostly apologising for not blogging more, so I’ll keep this short and sweet and simply announce some posts I’m working on:-
Why Go? - A post discussing the merits of Go and what makes it different from other programming languages.
Series: Algorithms - A series of posts on algorithms of interest, with a focus on exploring how you go about actually implementing them in code.
Series: Go Standard Library - A series of highly indulgent posts exploring Go’s standard libraries and how they are actually implemented in practice, in the vein of Jeff Atwood’s and Scott Hanselman’s recent posts on reading other’s source code.
Series: Go Internals - A series of yet more indulgent posts exploring Go’s internal implementation details.
Series: Weak and Chess Engines - A series of posts on the implementation of Weak and chess engines in general.
General Programming/Personal Topics of Interest - Basically whatever I happen to be thinking about at a given point. I think about programming a lot, and I think it’s time to put it out there, whether it’s coherent or of interest to other geeks out there, or not :-)
I am committing to getting at least one blog post out a week. I intend to fill my blog with exactly the kind of stuff I love reading in other people’s blogs - lots of juicy, no messing about, unix-bearded, hardcore tech detail and geekery with pride.
Sorry Brogrammers, I’ve got nothing for you.
久しぶりの翻訳更新です。
Go言語のインストールの翻訳を更新しました。
いままではGo言語をソースファイルから自分でコンパイルするしかなかったのですが、Version1からバイナリで配布されるようになりました。また、Windowsも正式にサポートされるようになりました。
Oddly appropriate, don't you think?
goinstall came about, and there has been a pretty significant uptick in discussion since the go tool began to take shape and the Go 1 release date approached. In talking with other Gophers at the GoSF meet-up recently, there doesn’t seem to be anyone who really has a good solution.
TL;DR: kylelemons.net/go/rx
Before I get too far, let me first summarize the problem.
When developing a Go application, you will most likely find yourself depending on another package, often written by another author. The ease of utilizing such third-party packages with the go tool makes this an even likelier scenario, and it is, in fact, encouraged. Inevitably, however, the author of some package on which you depend will make a change to his package; this could be anything from an innocuous bug fix to a large-scale API reorganization, and you are suddenly left with two choices: stick with the version you have (often by cloning it locally) or bite the bullet and update. This is complicated by the fact that you may both directly and indirectly depend on the same package, which means that both your project and your intermediate dependency need to agree on which of the above choices to take, and in a relatively timely manner.
There have been many proposals and complaints, both on- and offline, with respect to this problem. It’s not a problem that’s unique to Go, either; tools like Apache’s Maven, Ruby’s Bundler, etc all attempt to solve this problem to a greater or lesser degree. It is such a prevalent theme in development that a term, DLL Hell (and the more technically correct term dependency hell), has come into common use to describe it.
The most obvious thing to do is to be paranoid about package maintainers, and thus copy your dependencies into your project. If this strategy is sufficient, I highly recommend checking out goven, which will streamline this process (it even rewrites the imports!) for you. I take a different tack because I am lazy and don’t want to have to maintain other people’s code. I also don’t think this strategy simplifies the process of pulling in new changes from upstream, because you still have to update them one at a time until/unless something breaks.
The next obvious thing is to specify somewhere what version you want to check out, in the source code, so that go get knows about it and can do the right thing. This essentially boils down to something like import "path/package/version" (though various proposals suggest using @rev or similar). This is certainly a solution, and I suspect we will see tools emerge that will download source and update it to the proper revisions as a go get alternative. I didn’t choose this solution because this requires rewriting import paths when you update code and it makes it difficult to ensure that there is only a single version of a library built into the same binary, which can cause problems (if there are more, the init() calls will run twice, for one thing). It also doesn’t help with pulling in changes: you still are taking a chance that you’ll break something (sometimes without realizing it) whenever you pull from upstream.
Another reasonable strategy is to version-control the entire (or at least the dependencies within) GOPATH(s). This has the advantage that multiple developers always check out the correct versions, and branches and merges work nicely. A very simple tool along these lines is being developed as gogo, which allows you to version control your dependencies and share them between developers. As long as your version control system doesn’t mind having other version control systems’ (or its own) metadata stored inside it, this will work. The downside of this is that you are storing a lot of redundant data in your vcs, and it still doesn’t address the issue of how to figure out when and if you can update what packages.
So, since my ancient pre-goinstall build tool has been obsoleted, I figured I’d try my hand at distilling a reasonable, achievable set of goals out of the sea of requirements and suggestions and turn them into a tool for people to use. If you didn’t guess this from the previous section, the biggest problem that I think I can solve is helping you figure out what dependencies you can update without breaking your world. This can probably work in addition to at least a few of the strategies listed above for a more complete versioning solution, depending on your particular needs. Here are my informal design ideas/goals/requirements/notes:
go tool and GOPATH conventions as much as possible.In that vein, I have started work on rx, my prescription for your Go dependency version headaches. It’s starting to approach a few of the the requirements above already. To whet your appetite, here are a few examples of what it can do:
rx list will show you inter-repository dependenciesrx tags will show you the what tags are available in a repositoryrx prescribe will update a repository and test its transitive dependentsEach command also has plenty of fun options to play with; rx tags has, for instance, options to only show tags that are up- or downgrades. The structure of the program is strongly reminiscent of the design of the go tool (and, in fact, uses it for a lot of backend logic), and so should be familiar for most Gophers and fit nicely into your existing workflows.
Installation is, of course, rather simple:
go get -u kylelemons.net/go/rx
Here’s a brief example of using rx:
$ rx --rescan list | grep rpc /<gopath>/src/github.com/kylelemons/go-rpcgen: codec webrpc main main echoservice main main offload wire webrpc $ rx tags go-rpcgen | egrep v\|HEAD 193746c88dfebdc5462382b93c1038a29496d9af v2.0.0 a6938fa6ec0fb6a63fefab2c462d3cd1102cc477 v1.2.0 bf28cdf3e683dd0919800f6916141c17aa93c36d HEAD bf28cdf3e683dd0919800f6916141c17aa93c36d v1.1.0 f73c5c8ea85bdfbdc69e6aa24dd90b43c7265c67 v1.0.0 $ rx pre go-rpcgen v2.0.0 ok github.com/kylelemons/go-rpcgen/codec 0.051s ok github.com/kylelemons/go-rpcgen/examples/echo 0.139s ok github.com/kylelemons/go-rpcgen/examples/remote 0.019s ok github.com/kylelemons/blightbot/bot 0.029s ok github.com/kylelemons/go-paxos/paxos 0.053s $ rx tags go-rpcgen | egrep v\|HEAD 193746c88dfebdc5462382b93c1038a29496d9af HEAD 193746c88dfebdc5462382b93c1038a29496d9af v2.0.0 a6938fa6ec0fb6a63fefab2c462d3cd1102cc477 v1.2.0 bf28cdf3e683dd0919800f6916141c17aa93c36d v1.1.0 f73c5c8ea85bdfbdc69e6aa24dd90b43c7265c67 v1.0.0 </gopath>
There’s not a whole lot here, but you can see that the list command (in its short form) found the repository and listed the (short) names of the packages that exist under it. The --rescan option told it to actually scan my repositories, instead of using the cached dependency graph. The tags command then showed me the interesting tags in the repository (it’s git, so HEAD also shows where it was currently), and then the prescribe command updated it to the latest tag. Notice that the repository’s tests were run, as well as tests for packages that depended on packages in that repository (transitively). They were also built and installed (except binaries, by default), though this isn’t displayed unless you use the -v option.
To help elucidate the problem I’m trying to solve, here are a few use cases that I’d like to support.
As a single developer, you’ve probably got a single GOPATH into which all of your dependencies are installed alongside your own projects. You freely import between them, and everything generally works. You don’t run go get very often to pull down remote packages, unless you find a bug that has been fixed or you find a new feature in a newer library.
rx fetch command will let you fetch the latest changesets without actually applying them.rx tags --up command will show you what tags you can upgrade to.rx prescribe command will allow you to update to a new tag.rx prescribe command automatically builds and tests depenants transitively.rx prescribe command will roll back the update if it turns out to have broken something.As a small team working on a Go project, your concerns are much different from that of a single developer. You want your team members to easily stay in sync with one another, and you will only rarely pull changes in from upstream once you have your project working with a particular dependency.
--rxdir flag and RX_DIR environment variable let you version or share an rx configuration.rx cabinet --save command saves the versions of all repositories.rx cabinet --load command reverts/upgrades repositories to their saved state.rx cabinet --export command saves a relocatable cabinet that can be sshared.rx pin command lets you configure what repositories are considered for upgrade.rx auto command will try to upgrade packages automatically, keeping seamless upgrades.The common theme among these commands is maintaining a cohesive group of dependency versions. When you update a dependency (which we’ve seen that rx prescribe can do automatically), you can save that as a “known good” configuration that you can share, save, and (if things go south) restore later. For packages that are known to misbehave or for the package you’re editing, the rx pin command allows you to specify manually what behavior they should have (never upgrade, always tip, never change, etc). To help with exploring what updates might apply seamlessly, the rx auto command will do the heavy lifting of figuring out which repositories depend on each other and will successively try updates.
On a large project, you care about most of the same things as a small team, but there is also a good chance that you are working on multiple versions of your software simultaneously. There is also a good chance that any given developer may have multiple projects on his workstation which are independently versioned.
rx cabinet --exclude command (and friends) configure exactly what cabinets track.rx cabinet --diff command shows differences in dependencies between cabinets.rx prescribe optiosn can manage package upgrades auto can’t handle.The theme here is that the same commands that worked in a small and medium environment continue to work, but that their concepts can be extended (and modified slightly) to accomodate the needs of a larger development team. The larger the team is, the more chances are that there will be multiple branches in play, and rx will need to understand this.
There are still problems with this approach. As long as you start with a working project, you should generally be able to keep it working. You may not be able to ever update a package if one of its dependents never comes into line, though, which leads me to the biggest problem with this approach: it doesn’t make it easy to simply install a remote repository that has external dependencies. It’s intended primarily to support development and releasing of e.g. a binary, where your local development environment doesn’t matter to the end user. I’d like for there to be a nice way to import a package’s cabinet file when you’re importing it (so that your version of rx learns about what versions do and don’t work with various dependency versions), but I haven’t fully mapped this out.
Another problem which remains currently unsolved is the requirement to manually update when a dependency’s API changes. It would be nice to have some way for the author of a package to provide a way for dependent packages to fix themselves automatically; a tool like gofix. If this convention were widespread enough, it could vastly simplify the process of updating packages. This is something else about which I am thinking, and I hope that there are good libraries for easily making gofix-like tools in the future as well as a convention for including them in your projects.
There is a lot of work to do, but I think it’s at the point where the best feedback is feedback from real users who have a real need for a tool like this. The next priorities on my list are:
Your feedback, constructive criticism, and pull requests are all greatly appreciated!
P.S. I’m slowly cleaning up my many side-projects and making sure they work with Go 1. I’ll be listing them on kylelemons.net/go as I do, so feel free to e-mail me or find me on IRC if you have a favorite package that you want updated.
If you have written any Go code you have probably encountered the built-in error type. Go code uses error values to indicate an abnormal state. For example, the os.Open function returns a non-nil error value when it fails to open a file.
func Open(name string) (file *File, err error)
The following code uses os.Open to open a file. If an error occurs it calls log.Fatal to print the error message and stop.
f, err := os.Open("filename.ext")
if err != nil {
log.Fatal(err)
}
// do something with the open *File f You can get a lot done in Go knowing just this about the errortype, but in this article we'll take a closer look at error and discuss some good practices for error handling in Go.
The error type
The error type is an interface type. An errorvariable represents any value that can describe itself as a string. Here is the interface's declaration:
type error interface {
Error() string
} The error type, as with all built in types, is predeclared in the universe block.
The most commonly-used error implementation is the errors package's unexported errorString type.
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
You can construct one of these values with the errors.Newfunction. It takes a string that it converts to an errors.errorStringand returns as an error value.
// New returns an error that formats as the given text.
func New(text string) error {
return &errorString{text}
}
Here's how you might use errors.New:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// implementation
} A caller passing a negative argument to Sqrt receives a non-nil error value (whose concrete representation is an errors.errorString value). The caller can access the error string ("math: square root of...") by calling the error's Error method, or by just printing it:
f, err := Sqrt(-1)
if err != nil {
fmt.Println(err)
}
The fmt package formats an error value by calling its Error() string method.
It is the error implementation's responsibility to summarize the context. The error returned by os.Open formats as "open /etc/passwd: permission denied," not just "permission denied." The error returned by our Sqrt is missing information about the invalid argument.
To add that information, a useful function is the fmt package's Errorf. It formats a string according to Printf's rules and returns it as an error created by errors.New.
if f < 0 {
return 0, fmt.Errorf("math: square root of negative number %g", f)
} In many cases fmt.Errorf is good enough, but since error is an interface, you can use arbitrary data structures as error values, to allow callers to inspect the details of the error.
For instance, our hypothetical callers might want to recover the invalid argument passed to Sqrt. We can enable that by defining a new error implementation instead of using errors.errorString:
type NegativeSqrtError float64
func (f NegativeSqrtError) Error() string {
return fmt.Sprintf("math: square root of negative number %g", float64(f))
}
A sophisticated caller can then use a type assertion to check for a NegativeSqrtError and handle it specially, while callers that just pass the error to fmt.Println or log.Fatal will see no change in behavior.
As another example, the json package specifies a SyntaxError type that the json.Decode function returns when it encounters a syntax error parsing a JSON blob.
type SyntaxError struct {
msg string // description of error
Offset int64 // error occurred after reading Offset bytes
}
func (e *SyntaxError) Error() string { return e.msg } The Offset field isn't even shown in the default formatting of the error, but callers can use it to add file and line information to their error messages:
if err := dec.Decode(&val); err != nil {
if serr, ok := err.(*json.SyntaxError); ok {
line, col := findLine(f, serr.Offset)
return fmt.Errorf("%s:%d:%d: %v", f.Name(), line, col, err)
}
return err
} (This is a slightly simplified version of some actual codefrom the Camlistore project.)
The error interface requires only a Error method; specific error implementations might have additional methods. For instance, the net package returns errors of type error, following the usual convention, but some of the error implementations have additional methods defined by the net.Errorinterface:
package net
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}
Client code can test for a net.Error with a type assertion and then distinguish transient network errors from permanent ones. For instance, a web crawler might sleep and retry when it encounters a temporary error and give up otherwise.
if nerr, ok := err.(net.Error); ok && nerr.Temporary() {
time.Sleep(1e9)
continue
}
if err != nil {
log.Fatal(err)
} Simplifying repetitive error handling
In Go, error handling is important. The language's design and conventions encourage you to explicitly check for errors where they occur (as distinct from the convention in other languages of throwing exceptions and sometimes catching them). In some cases this makes Go code verbose, but fortunately there are some techniques you can use to minimize repetitive error handling.
Consider an App Engineapplication with an HTTP handler that retrieves a record from the datastore and formats it with a template.
func init() {
http.HandleFunc("/view", viewRecord)
}
func viewRecord(w http.ResponseWriter, r *http.Request) {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
http.Error(w, err.Error(), 500)
return
}
if err := viewTemplate.Execute(w, record); err != nil {
http.Error(w, err.Error(), 500)
}
} This function handles errors returned by the datastore.Getfunction and viewTemplate's Execute method. In both cases, it presents a simple error message to the user with the HTTP status code 500 ("Internal Server Error"). This looks like a manageable amount of code, but add some more HTTP handlers and you quickly end up with many copies of identical error handling code.
To reduce the repetition we can define our own HTTP appHandlertype that includes an error return value:
type appHandler func(http.ResponseWriter, *http.Request) error
Then we can change our viewRecord function to return errors:
func viewRecord(w http.ResponseWriter, r *http.Request) error {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
return err
}
return viewTemplate.Execute(w, record)
} This is simpler than the original version, but the http package doesn't understand functions that return error. To fix this we can implement the http.Handler interface's ServeHTTP method on appHandler:
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if err := fn(w, r); err != nil {
http.Error(w, err.Error(), 500)
}
} The ServeHTTP method calls the appHandler function and displays the returned error (if any) to the user. Notice that the method's receiver, fn, is a function. (Go can do that!) The method invokes the function by calling the receiver in the expression fn(w, r).
Now when registering viewRecord with the http package we use the Handle function (instead of HandleFunc) as appHandler is an http.Handler (not an http.HandlerFunc).
func init() {
http.Handle("/view", appHandler(viewRecord))
} With this basic error handling infrastructure in place, we can make it more user friendly. Rather than just displaying the error string, it would be better to give the user a simple error message with an appropriate HTTP status code, while logging the full error to the App Engine developer console for debugging purposes.
To do this we create an appError struct containing an error and some other fields:
type appError struct {
Error error
Message string
Code int
} Next we modify the appHandler type to return *appError values:
type appHandler func(http.ResponseWriter, *http.Request) *appError
(It's usually a mistake to pass back the concrete type of an error rather than error, for reasons discussed in the Go FAQ, but it's the right thing to do here because ServeHTTP is the only place that sees the value and uses its contents.)
And make appHandler's ServeHTTP method display the appError's Message to the user with the correct HTTP status Code and log the full Error to the developer console:
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if e := fn(w, r); e != nil { // e is *appError, not os.Error.
c := appengine.NewContext(r)
c.Errorf("%v", e.Error)
http.Error(w, e.Message, e.Code)
}
} Finally, we update viewRecord to the new function signature and have it return more context when it encounters an error:
func viewRecord(w http.ResponseWriter, r *http.Request) *appError {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
return &appError{err, "Record not found", 404}
}
if err := viewTemplate.Execute(w, record); err != nil {
return &appError{err, "Can't display record", 500}
}
return nil
} This version of viewRecord is the same length as the original, but now each of those lines has specific meaning and we are providing a friendlier user experience.
It doesn't end there; we can further improve the error handling in our application. Some ideas:
appError that stores the stack trace for easier debugging, appHandler, logging the error to the console as "Critical," while telling the user "a serious error has occurred." This is a nice touch to avoid exposing the user to inscrutable error messages caused by programming errors. See the Defer, Panic, and Recoverarticle for more details. Conclusion
Proper error handling is an essential requirement of good software. By employing the techniques described in this post you should be able to write more reliable and succinct Go code.

QR codes are 2-dimensional bar codes that encode arbitrary text strings. A common use of QR codes is to encode URLs so that people can scan a QR code (for example, on an advertising poster, building roof, volleyball bikini, belt buckle, or airplane banner) to load a web site on a cell phone instead of having to “type” in a URL.
QR codes are encoded using Reed-Solomon error-correcting codes, so that a QR scanner does not have to see every pixel correctly in order to decode the content. The error correction makes it possible to introduce a few errors (fewer than the maximum that the algorithm can fix) in order to make an image. For example, in 2008, Duncan Robertson took a QR code for “http://bbc.co.uk/programmes” (left) and introduced errors in the form of a BBC logo (right):

That's a neat trick and a pretty logo, but it's uninteresting from a technical standpoint. Although the BBC logo pixels look like QR code pixels, they are not contribuing to the QR code. The QR reader can't tell much difference between the BBC logo and the Union Jack. There's just a bunch of noise in the middle either way.

Since the BBC QR logo appeared, there have been many imitators. Most just slap an obviously out-of-place logo in the middle of the code. This Disney poster is notable for being more in the spirit of the BBC code.
There's a different way to put pictures in QR codes. Instead of scribbling on redundant pieces and relying on error correction to preserve the meaning, we can engineer the encoded values to create the picture in a code with no inherent errors, like these:




This post explains the math behind making codes like these, which I call QArt codes. I have published the Go programs that generated these codes at code.google.com/p/rsc and created a web site for creating these codes.
For error correction, QR uses Reed-Solomon coding (like nearly everything else). For our purposes, Reed-Solomon coding has two important properties. First, it is what coding theorists call a systematic code: you can see the original message in the encoding. That is, the Reed-Solomon encoding of “hello” is “hello” followed by some error-correction bytes. Second, Reed-Solomon encoded messages can be XOR'ed: if we have two different Reed-Solomon encoded blocks b1 and b2 corresponding to messages m1 and m2, b1 ⊕ b2 is also a Reed-Solomon encoded block; it corresponds to the message m1 ⊕ m2. (Here, ⊕ means XOR.) If you are curious about why these two properties are true, see my earlier post, Finite Field Arithmetic and Reed-Solomon Coding.
A QR code has a distinctive frame that help both people and computers recognize them as QR codes. The details of the frame depend on the exact size of the code—bigger codes have room for more bits—but you know one when you see it: the outlined squares are the giveaway. Here are QR frames for a sampling of sizes:

The colored pixels are where the Reed-Solomon-encoded data bits go. Each code may have one or more Reed-Solomon blocks, depending on its size and the error correction level. The pictures show the bits from each block in a different color. The L encoding is the lowest amount of redundancy, about 20%. The other three encodings increase the redundancy, using 38%, 55%, and 65%.

(By the way, you can read the redundancy level from the top pixels in the two leftmost columns. If black=0 and white=1, then you can see that 00 is L, 01 is M, 10 is Q, and 11 is H. Thus, you can tell that the QR code on the T-shirt in this picture is encoded at the highest redundancy level, while this shirt uses the lowest level and therefore might take longer or be harder to scan.
As I mentioned above, the original message bits are included directly in the message's Reed-Solomon encoding. Thus, each bit in the original message corresponds to a pixel in the QR code. Those are the lighter pixels in the pictures above. The darker pixels are the error correction bits. The encoded bits are laid down in a vertical boustrophedon pattern in which each line is two columns wide, starting at the bottom right corner and ending on the left side:

We can easily work out where each message bit ends up in the QR code. By changing those bits of the message, we can change those pixels and draw a picture. There are, however, a few complications that make things interesting.
The first complication is that the encoded data is XOR'ed with an obfuscating mask to create the final code. There are eight masks:

An encoder is supposed to choose the mask that best hides any patterns in the data, to keep those patterns from being mistaken for framing boxes. In our encoder, however, we can choose a mask before choosing the data. This violates the spirit of the spec but still produces legitimate codes.
The second complication is that we want the QR code's message to be intelligible. We could draw arbitrary pictures using arbitrary 8-bit data, but when scanned the codes would produce binary garbage. We need to limit ourselves to data that produces sensible messages. Luckily for us, QR codes allow messages to be written using a few different alphabets. One alphabet is 8-bit data, which would require binary garbage to draw a picture. Another is numeric data, in which every run of 10 bits defines 3 decimal digits. That limits our choice of pixels slightly: we must not generate a 10-bit run with a value above 999. That's not complete flexibility, but it's close: 9.96 bits of freedom out of 10. If, after encoding an image, we find that we've generated an invalid number, we pick one of the 5 most significant bits at random—all of them must be 1s to make an invalid number—hard wire that bit to zero, and start over.
Having only decimal messages would still not be very interesting: the message would be a very large number. Luckily for us (again), QR codes allow a single message to be composed from pieces using different encodings. The codes I have generated consist of an 8-bit-encoded URL ending in a # followed by a numeric-encoded number that draws the actual picture:
The leading URL is the first data encoded; it takes up the right side of the QR code. The error correction bits take up the left side.
When the phone scans the QR code, it sees a URL; loading it in a browser visits the base page and then looks for an internal anchor on the page with the given number. The browser won't find such an anchor, but it also won't complain.
The techniques so far let us draw codes like this one:


The second copy darkens the pixels that we have no control over: the error correction bits on the left and the URL prefix on the right. I appreciate the cyborg effect of Peter melting into the binary noise, but it would be nice to widen our canvas.
The third complication, then, is that we want to draw using more than just the slice of data pixels in the middle of the image. Luckily, we can.
I mentioned above that Reed-Solomon messages can be XOR'ed: if we have two different Reed-Solomon encoded blocks b1 and b2 corresponding to messages m1 and m2, b1 ⊕ b2 is also a Reed-Solomon encoded block; it corresponds to the message m1 ⊕ m2. (In the notation of the previous post, this happens because Reed-Solomon blocks correspond 1:1 with multiples of g(x). Since b1 and b2 are multiples of g(x), their sum is a multiple of g(x) too.) This property means that we can build up a valid Reed-Solomon block from other Reed-Solomon blocks. In particular, we can construct the sequence of blocks b0, b1, b2, ..., where bi is the block whose data bits are all zeros except for bit i and whose error correction bits are then set to correspond to a valid Reed-Solomon block. That set is a basis for the entire vector space of valid Reed-Solomon blocks. Here is the basis matrix for the space of blocks with 2 data bytes and 2 checksum bytes:
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
The missing entries are zeros. The gray columns highlight the pixels we have complete control over: there is only one row with a 1 for each of those pixels. Each time we want to change such a pixel, we can XOR our current data with its row to change that pixel, not change any of the other controlled pixels, and keep the error correction bits up to date.
So what, you say. We're still just twiddling data bits. The canvas is the same.
But wait, there's more! The basis we had above lets us change individual data pixels, but we can XOR rows together to create other basis matrices that trade data bits for error correction bits. No matter what, we're not going to increase our flexibility—the number of pixels we have direct control over cannot increase—but we can redistribute that flexibility throughout the image, at the same time smearing the uncooperative noise pixels evenly all over the canvas. This is the same procedure as Gauss-Jordan elimination, the way you turn a matrix into row-reduced echelon form.
This matrix shows the result of trying to assert control over alternating pixels (the gray columns):
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
| 1 | 1 | 1 | 1 | ||||||||||||||||||||||||||||
The matrix illustrates an important point about this trick: it's not completely general. The data bits are linearly independent, but there are dependencies between the error correction bits that mean we often can't have every pixel we ask for. In this example, the last four pixels we tried to get were unavailable: our manipulations of the rows to isolate the first four error correction bits zeroed out the last four that we wanted.
In practice, a good approach is to create a list of all the pixels in the Reed-Solomon block sorted by how useful it would be to be able to set that pixel. (Pixels from high-contrast regions of the image are less important than pixels from low-contrast regions.) Then, we can consider each pixel in turn, and if the basis matrix allows it, isolate that pixel. If not, no big deal, we move on to the next pixel.
Applying this insight, we can build wider but noisier pictures in our QR codes:


The pixels in Peter's forehead and on his right side have been sacrificed for the ability to draw the full width of the picture.
We can also choose the pixels we want to control at random, to make Peter peek out from behind a binary fog:



One final trick. QR codes have no required orientation. The URL base pixels that we have no control over are on the right side in the canonical orientation, but we can rotate the QR code to move them to other edges.




All the source code for this post, including the web server, is at code.google.com/p/rsc/source/browse/qr. If you liked this, you might also like Zip Files All The Way Down.
Alex Healy pointed out that valid Reed-Solomon encodings are closed under XOR, which is the key to spreading the picture into the error correction pixels. Peter Weinberger has been nothing but gracious about the overuse of his binary likeness. Thanks to both.
Since the biggest problem with transport security is that most sites don't use it, anything that reduces the latency impact of HTTPS is important. Making things faster doesn't just make them faster, it also makes them cheaper and more prevalent. When HTTPS is faster, it'll be used in more places than it would otherwise be.
But, sadly, False Start will be disabled, except for sites doing NPN, in Chrome 20. NPN is a TLS extension that we use to negotiate SPDY, although you don't have to use it to negotiate SPDY, you can advertise http/1.1 if you wish.
False Start was known to cause problems with a very small number of servers and the initial announcement outlined the uncommon scheme that we used to deploy it: we scanned the public Internet and built up a list of problematic sites. That list was built into Chrome and we didn't use False Start for connections to those sites. Over time the list was randomly eroded away and I'd try to address any issues that came up. (Preemptively so in the case of large sites.)
It did work to some extent. Many sites that had problems were fixed and it's a deployment scheme that is worth considering in the future. But it didn't ultimately work well enough for False Start.
Initially we believed that False Start issues were deterministic so long as the TLS Finished and application data records were sent in the same TCP packet. We changed Chrome to do this in the hopes of making False Start issues deterministic. However, we later discovered some HTTPS servers that were still non-deterministically False Start intolerant. I hypothesise that the servers run two threads per connection: one for reading and one for writing. Although the TCP packet was received atomically, thread scheduling could mean that the read thread may or may not be scheduled before the write thread had updated the connection state in response to the Finished.
This non-determinism made False Start intolerance difficult to diagnose and reduced our confidence in the blacklist.
The `servers' with problems were nearly always SSL terminators. These hardware devices terminate SSL connections and proxy unencrypted data to backend HTTP servers. I believe that False Start intolerance is very simple to fix in the code and one vendor suggested that was the case. None the less, of the vendors who did issue an update, most failed to communicate that fact to their customers. (A pattern that has repeated with the BEAST fix.)
One, fairly major, SSL terminator vendor refused to update to fix their False Start intolerance despite problems that their customers were having. I don't believe that this was done in bad faith, but rather a case of something much more mundane along the lines of “the SSL guy left and nobody touches that code any more”. However, it did mean that there was no good answer for their customers who were experiencing problems.
Lastly, it was becoming increasingly clear that we had a bigger problem internationally. Foreign admins have problems finding information on the subject (which is mostly in English) and foreign users have problems reporting bugs because we can't read them. We do have excellent agents in countries who liaise locally but it was still a big issue, and we don't cover every country with them. I also suspect that the distribution of problematic SSL terminators is substantially larger in some countries and that the experience with the US and Europe caused us to underestimate the problem.
In aggregate this lead us to decide that False Start was causing more problems than it was worth. We will now limit it to sites that support the NPN extension. This unfortunately means that it'll be an arcane, unused optimisation for the most part: at least until SPDY takes over the world.
Finite fields are a branch of algebra formally defined in the 1820s, but interest in the topic can be traced back to public sixteenth-century polynomial-solving contests. For the next few centuries, finite fields had little practical value, but all changed in the last fifty years. It turns out that they are useful for many applications in modern computing, such as encryption, data compression, and error correction.
In particular, Reed-Solomon codes are an error-correcting code based on finite fields and used everywhere today. One early significant use was in the Voyager spacecraft: the messages it still sends back today, from the edge of the solar system, are heavily Reed-Solomon encoded so that even if only a small fragment makes it back to Earth, we can still reconstruct the message. Reed-Solomon coding is also used on CDs to withstand scratches, in wireless communications to withstand transmission problems, in QR codes to withstand scanning errors or smudges, in disks to withstand loss of fragments of the media, in high-level storage systems like Google's GFS and BigTable to withstand data loss and also to reduce read latency (the read can complete without waiting for all the responses to arrive).
This post shows how to implement finite field arithmetic efficiently on a computer, and then how to use that to implement Reed-Solomon encoding.
One way mathematicians study numbers is to abstract away the numbers themselves and focus on the operations. (This is kind of an object-oriented approach to math.) A field is defined as a set F and operators + and · on elements of F that satisfy the following properties:
You probably recognize those properties from high school algebra class: the most well-known example of a field is the real numbers, where + is addition and · is multiplication. Other examples are complex numbers and fractions.
A mathematician doesn't have to prove the same results over and over
for the real numbers ℝ, the complex numbers ℂ, the fractions ℚ, and so on.
Instead, she can prove that a particular result holds for all fields—by assuming only
the above properties, called the field axioms. Then she can apply the result by
substituting a specific instance like the real numbers for the general idea of a field,
the same way that a programmer can implement just one vector(T)
and then instantiate it as vector(int), vector(string) and so on.
The integers ℤ are not a field: they lack multiplicative inverses. For example, there is no number that you can multiply by 2 to get 1, no 1/2. Surprisingly, though, the integers modulo any prime p do form a field. For example, the integers modulo 5 are 0, 1, 2, 3, 4. 1+4 = 0 (mod 5), so we say that 4 = −1. Similarly, 2·3 = 1 (mod 5), so we say that 3 = 1/2. After we've proved that ℤ/p is in fact a field, all the results about fields can be applied to ℤ/p. This is very useful: it lets us apply our intuition about the very familiar real numbers to these less familiar numbers. This field is written ℤ/p to emphasize that we're dealing with what's left after subtracting out all the p's. That is, we're dealing with what's left if you assume that p = 0. When you make that assumption, you get math that wraps around at p. These fields are called finite fields because, in contrast to fields like the real numbers, they have a finite number of elements.
For a programmer, the most interesting finite field is
ℤ/2, which contains just the integers 0, 1. Addition
is the same as XOR, and multiplication is the same as AND.
Note that ℤ/p is only a field when p is prime:
arithmetic on uint8 variables corresponds
to ℤ/256, but it is not a field: there is no 1/2.
The only problem with fields is that there's not a ton you can do with just the field axioms. One thing you can do is build polynomials, which were the original motivation for the mathematicians who pioneered the use of fields in the early 1800s. If we introduce a symbolic variable x, then we can build polynomials whose coefficients are field values. We'll write F[x] to denote the polynomials over x using coefficients from F. For example, if we use the real numbers ℝ as our field, then the polynomials ℝ[x] include x2+1, x+2, and 3.14x2 − 2.72x + 1.41. Like integers, these polynomials can be added and multiplied, but not always divided—what is (x2+1)/(x+2)?—so they are not a field. However, remember how the integers are not a field but the integers modulo a prime are a field? The same happens here: polynomials are not a field but polynomials modulo some prime polynomial are.
What does “polynomials modulo some prime polynomial” mean anyway? A prime polynomial is one that cannot be factored, like x2+1 cannot be factored using real numbers. The field ℤ/5 is what you get by doing math under the assumption that 5 = 0; similarly, ℝ[x]/(x2+1) is what you get by doing math under the assumption that x2+1 = 0. Just as ℤ/5 math never deals with numbers as big as 5, ℝ[x]/(x2+1) math never deals with polynomials as big as x2: anything bigger can have some multiple of x2+1 subtracted out again. That is, the polynomials in ℝ[x]/(x2+1) are bounded in size: they have only x1 and x0 (constant) terms. To add polynomials, we just add the coefficients using the addition rule from the coefficient's field, independently, like a vector addition. To multiply polynomials, we have to do the multiplication and then subtract out any x2+1 we can. If we have (ax+b)·(cx+d), we can expand this to (a·c)x2 + (b·c+a·d)x + (b·d), and then subtract (a·c)(x2+1) = (a·c)x2 + (a·c), producing the final result: (b·c+a·d)x + (b·d−a·c). That might seem like a funny definition of multiplication, but it does in fact obey the field axioms. In fact, this particular field is more familiar than it looks: it is the complex numbers ℂ, but we've written x instead of the usual i. Assuming that x2+1 = 0 is, except for a renaming, the same as defining i2 = −1.
Doing all our math modulo a prime polynomial let us take the field of real numbers and produce a field whose elements are pairs of real numbers. We can apply the same trick to take a finite field like ℤ/p and product a field whose elements are fixed-length vectors of elements of ℤ/p. The original ℤ/p has p elements. If we construct (ℤ/p)[x]/f(x), where f(x) is a prime polynomial of degree n (f's maximum x exponent is n), the resulting field has pn elements: all the vectors made up of n elements from ℤ/p. Incredibly, the choice of prime polynomial doesn't matter very much: any two finite fields of size pn have identical structure, even if they give the individual elements different names. Because of this, it makes sense to refer to all the finite fields of size pn as one concept: GF(pn). The GF stands for Galois Field, in honor of Évariste Galois, who was the first to study these. The exact polynomial chosen to produce a particular GF(pn) is an implementation detail.
For a programmer, the most interesting finite fields constructed this way are GF(2n)—the polynomial extensions of ℤ/2—because the elements of GF(2n) are bit vectors of length n. As a concrete example, consider (ℤ/2)[x]/(x8+x4+x3+x+1) . The field has 28 elements: each can be represented by a single byte. The byte with binary digits b7b6b5b4b3b2b1b0 represents the polynomial b7·x7 + b6·x6 + b5·x5 + b4·x4 + b3·x3 + b2·x2 + b1·x1 + b0. To add polynomials, we add coefficients. Since the coefficients are from ℤ/2, adding coefficients means XOR'ing each bit position separately, which is something computer hardware can do easily. Multiplying the polynomials is more difficult, because standard multiplication hardware is based on adding, but we need a multiplication based on XOR'ing. Because the coefficient math wraps at 2, (x2+x)·(x+1) = x3+2x2+x = x3+x, while computer multiplication would choose 1102* 0112 = 6 * 3 = 18 = 100102. However, it turns out that we can implement this field multiplication with a simple lookup table. In a finite field, there is always at least one element α that can serve as a generator. All the other non-zero elements are powers of α: α, α2, α3, and so on. This α is not symbolic like x: it's a specific element. For example, in ℤ/5, we can use α=2: {α, α2, α3, α4} = {2, 4, 8, 16} = {2, 4, 3, 1}. In GF(2n) the math is more complex but still works. If we know the generator, then we can, by repeated multiplication, create a lookup table exp[i] = αⁱ and an inverse table log[αⁱ] = i. Multiplication is then just a few table lookups: assuming a and b are non-zero, a·b = exp[log[a]+log[b]]. (That's a normal integer +, to add the exponents, not an XOR.)
The fact that GF(2n) can be implemented efficiently on a computer means that we can implement systems based on mathematical theorems without worrying about the usual overflow problems you get when modeling integers or real numbers. To be sure, GF(2n) behaves quite differently from the integers in many ways, but if all you need is the field axioms, it's good enough, and it eliminates any need to worry about overflow or arbitrary precision calculations. Because of the lookup table, GF(28) is by far the most common choice of field in a computer algorithm. For example, the Advanced Encryption Standard (AES, formerly Rijndael) is built around GF(28) arithmetic, as are nearly all implementations of Reed-Solomon coding.
Let's begin by defining a Field type that will
represent the specific instance of GF(28) defined by a
given polynomial.
The polynomial must be of degree 8, meaning that
its binary representation has the 0x100 bit set and no
higher bits set.
type Field struct {
...
}
Addition is just XOR, no matter what the polynomial is:
// Add returns the sum of x and y in the field.
func (f *Field) Add(x, y byte) byte {
return x ^ y
}
Multiplication is where things get interesting. If you'd used binary (and Go) in grade school, you might have learned this algorithm for multiplying two numbers (this is not finite field arithmetic):
// Grade-school multiplication in binary: mul returns the product x×y.
func mul(x, y int) int {
z := 0
for x > 0 {
if x&1 != 0 {
z += y
}
x >>= 1
y <<= 1
}
return z
}
The running total z accumulates the product of x and y.
The first iteration of this loop adds y to z if the
low bit (the 1s digit) of x is 1.
The next iteration adds y*2 if the next bit (the 2s digit, now shifted down) of
x is 1.
The next iteration adds y*4 if the 4s digit is 1, and so on.
Each iteration shifts x to the right to chop off the processed digit
and shifts y to the left to multiply by two.
To adapt this to multiply in a finite field, we need to make two changes.
First, addition is XOR, so we use ^= instead of +=
to add to z.
Second, we need to make the multiply reduce modulo the polynomial.
Assuming that the inputs have already been reduced, the only chance
of exceeding the polynomial comes from the shift of y.
After the shift, then, we can check to see if we've overflowed, and if so,
subtract (XOR) out one copy of the polynomial.
The finite field version, then, is:
// GF(256) mutiplication: mul returns the product x×y mod poly.
func mul(x, y, poly int) int {
z := 0
for x > 0 {
if x&1 != 0 {
z ^= y
}
x >>= 1
y <<= 1
if y&0x100 != 0 {
y ^= poly
}
}
return z
}
We might want to do a lot of multiplication, though,
and this loop is too slow. There aren't that many inputs—only 28×28 of them—so one
option is to build a 64kB lookup table. With some cleverness, we can
build a smaller lookup table.
In the NewField
constructor, we can compute α0, α1, α2, ..., record the sequence
in an exp array, and record the inverse in
a log array.
Then we can reduce multiplication to addition of logarithms,
like a slide rule does.
// A Field represents an instance of GF(256) defined by a specific polynomial.
type Field struct {
log [256]byte // log[0] is unused
exp [510]byte
}
// NewField returns a new field corresponding to
// the given polynomial and generator.
func NewField(poly, α int) *Field {
var f Field
x := 1
for i := 0; i < 255; i++ {
f.exp[i] = byte(x)
f.exp[i+255] = byte(x)
f.log[x] = byte(i)
x = mul(x, α, poly)
}
f.log[0] = 255
return &f
}
The values of the exp function cycle with period 255
(not 256, because 0 is impossible): α255 = 1.
The straightforward way to implement Exp, then,
is to look up the entry given by the exponent modulo 255.
// Exp returns the base 2 exponential of e in the field.
// If e < 0, Exp returns 0.
func (f *Field) Exp(e int) byte {
if e < 0 {
return 0
}
return f.exp[e%255]
}
Log is an even simpler table lookup, because the input
is only a byte:
// Log returns the base 2 logarithm of x in the field.
// If x == 0, Log returns -1.
func (f *Field) Log(x byte) int {
if x == 0 {
return -1
}
return int(f.log[x])
}
Mul is where things get interesting.
The obvious implementation of Mul is exp[(log[x]+log[y])%255],
but if we double the exp array, so that it is 510 elements long,
we can drop the relatively expensive %255:
// Mul returns the product of x and y in the field.
func (f *Field) Mul(x, y byte) byte {
if x == 0 || y == 0 {
return 0
}
return f.exp[int(f.log[x])+int(f.log[y])]
}
Inv returns the multiplicative inverse, 1/x.
We don't implement divide: instead of x/y, we can use x · 1/y.
// Inv returns the multiplicative inverse of x in the field.
// If x == 0, Inv returns 0.
func (f *Field) Inv(x byte) byte {
if x == 0 {
return 0
}
return f.exp[255-f.log[x]]
}
In 1960, Irving Reed and Gustave Solomon proposed a way to build an error-correcting code using GF(2n). The method interpreted the m message bits as coefficients of a polynomial f of degree m−1 over GF(2n) and then sent f(0), f(α), f(α2), f(α3), ..., f(1). Any m of these, if received correctly, suffice to reconstruct f, and then the message can be read off the coefficients. To find a correct set, Reed and Solomon's algorithm constructed the f corresponding to every possible subset of m received values and then chose the most common one in a majority vote. As long as no more than (2n−m)/2 values were corrupted in transit, the majority will agree on the correct value of f. This decoding algorithm is very expensive, too expensive for long messages. As a result, the Reed-Solomon approach sat unused for almost a decade. In 1969, however, Elwyn Berlekamp and James Massey proposed a variant with an efficient decoding algorithm. In the 1980s, Berlekamp and Lloyd Welch developed an even more efficient decoding algorithm that is the one typically used today. These decoding algorithms are based on systems of equations far too complex to explain here; in this post, we will only deal with encoding. (I can't keep the decoding algorithms straight in my head for more than an hour or two at a time, much less explain them in finite space.)
In Reed-Solomon encoding as it is practiced today, the choice of finite field F and generator α defines a generator polynomial g(x) = (x−1)(x−α)(x−α2)...(x−αn−m). To encode a message m, the message is taken as the top coefficients of a degree n polynomial f(x) = m0xn−1+m1xn−2+...+mmxn−m−1. Then that polynomial can be divided by g to produce the remainder polynomial r(x), the unique polynomial of degree less than n−m such that f(x) − r(x) is a multiple of g(x). Since r(x) is of degree less than n−m, subtracting r(x) does not affect any of the message coefficients, just the lower terms, so the polynomial f(x) − r(x) (= f(x) + r(x)) is taken as the encoded message. All encoded messages, then, are multiples of g(x). On the receiving end, the decoder does some magic to figure out the simplest changes needed to make the received polynomial a multiple of g(x) and then reads the message out of the top coefficients.
While decoding is difficult, encoding is easy: the first m bytes are the message itself, followed by the c bytes defining the remainder of m·xc/g(x). We can also check whether we received an error-free message by checking whether the concatenation defines a polynomial that is a multiple of g(x).
The Reed-Solomon encoding problem is this: given a message m interpreted as a polynomial m(x), compute the error correction bytes, m(x)·xc mod g(x).
The grade-school division algorithm works well here.
If we fill in p with m(x)·xc (m followed by c zero bytes),
then we can replace p by the remainder by iteratively subtracting out
multiples of the generator polynomial g.
for i := 0; i < len(m); i++ {
k := f.Mul(p[i], f.Inv(gen[0])) // k = pi / g0
// p -= k·g
for j, g := range gen {
p[i+j] = f.Add(p[i+j], f.Mul(k, g))
}
}
This implementation is correct but can be made more efficient. If you want to try, run:
go get code.google.com/p/rsc/gf256 go test code.google.com/p/rsc/gf256 -bench Blog
That benchmark measures
the speed of the implementation in blog_test.go,
which looks like the above. Optimize away, or follow along.
There's definitely room for improvement:
$ go test code.google.com/p/rsc/gf256 -bench ECC PASS BenchmarkBlogECC 500000 7031 ns/op 4.55 MB/s BenchmarkECC 1000000 1332 ns/op 24.02 MB/s
To start, we can expand the definitions of Add and Mul.
The Go compiler's inliner would do this for us; the win here is not
the inlining but the simplifications it will enable us to make.
for i := 0; i < len(m); i++ {
if p[i] == 0 {
continue
}
k := f.exp[f.log[p[i]] + 255 - f.log[gen[0]]] // k = pi / g0
// p -= k·g
for j, g := range gen {
p[i+j] ^= f.exp[f.log[k] + f.log[g]]
}
}
(The implementation handles p[i] == 0 specially
because 0 has no log.)
The first thing to note is that we compute k but then use
f.log[k] repeatedly. Computing the log will avoid that
memory access, and it is cheaper: we just take out the f.exp[...] lookup
on the line that computes k. This is safe because p[i] is non-zero, so k must be non-zero.
for i := 0; i < len(m); i++ {
if p[i] == 0 {
continue
}
lk := f.log[p[i]] + 255 - f.log[gen[0]] // k = pi / g0
// p -= k·g
for j, g := range gen {
p[i+j] ^= f.exp[lk + f.log[g]]
}
}
Next, note that we repeatedly compute f.log[g]. Instead of doing that,
we can iterate lgen—an array holding the logs of the coefficients—instead of gen.
We'll have to handle zero somehow: let's say that the array has an entry set to 255
when the corresponding gen value is zero.
for i := 0; i < len(m); i++ {
if p[i] == 0 {
continue
}
lk := f.log[p[i]] + 255 - f.log[gen[0]] // k = pi / g0
// p -= k·g
for j, lg := range lgen {
if lg != 255 {
p[i+j] ^= f.exp[lk + lg]
}
}
}
Next, we can notice that since the generator is defined as
the first coefficient, g0, is always 1! That means we can simplify the k = pi / g calculation to just k = pi. Also, we can drop the first element of lgen and its subtraction, as long as we ignore the high bytes in the result (we know they're supposed to be zero anyway).
for i := 0; i < len(m); i++ {
if p[i] == 0 {
continue
}
lk := f.log[p[i]]
// p -= k·g
for j, lg := range lgen {
if lg != 255 {
p[i+1+j] ^= f.exp[lk + lg]
}
}
}
The inner loop, which is where we spend all our time, has two
additions by loop-invariant constants: i+1+j and lk+lg.
The i+1 and lk do not change on each iteration.
We can avoid those additions by reslicing the arrays
outside the loop:
for i := 0; i < len(m); i++ {
if p[i] == 0 {
continue
}
lk := f.log[p[i]]
// p -= k·g
q := p[i+1:]
exp := f.exp[lk:]
for j, lg := range lgen {
if lg != 255 {
q[j] ^= exp[lg]
}
}
}
As one final trick, we can replace p[i] by a range variable.
The Go compiler does not yet use
loop invariants to eliminate bounds checks, but it does eliminate
bounds checks in the implicit indexing done by a range loop.
for i, pi := range p {
if i == len(m) {
break
}
if pi == 0 {
continue
}
// p -= k·g
q := p[i+1:]
exp := f.exp[f.log[pi]:]
for j, lg := range lgen {
if lg != 255 {
q[j] ^= exp[lg]
}
}
}
The code is in context in gf256.go.
We started with single bits 0 and 1. From those we constructed 8-bit polynomials—the elements of GF(28)—with overflow-free, easy-to-implement mathematical operations. From there we moved on to Reed-Solomon coding, which constructs its own polynomials built using elements of GF(28) as coefficients. That is, each Reed-Solomon message is interpreted as a polynomial, and each coefficient in that polynomial is itself a smaller polynomial.
Now that we know how to create Reed-Solomon encodings, the next post will look at some fun we can have with them.
i = (data[0]<<0) | (data[1]<<8) | (data[2]<<16) | (data[3]<<24);
i = (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24);
i = *((int*)data);#ifdef BIG_ENDIAN/* swap the bytes */i = ((i&0xFF)<<24) | (((i>>8)&0xFF)<<16) | (((i>>16)&0xFF)<<8) | (((i>>24)&0xFF)<<0);#endif
A hash function for a particular hash table should always be deterministic, right? At least, that's what I thought until a few weeks ago, when I was able to fix a performance problem by calling rand inside a hash function.
A hash table is only as good as its hash function, which ideally satisfies two properties for any key pair k1, k2:
Normally, following rule 1 would prohibit the use of random bits while computing the hash, because if you pass in the same key again, you'd use different random bits and get a different hash value. That's why the fact that I got to call rand in a hash function is so surprising.
If the hash function violates rule 1, your hash table just breaks: you can't find things you put in, because you are looking in the wrong places. If the hash function satisfies rule 1 but violates rule 2 (for example, “return 42”), the hash table will be slow due to the large number of hash collisions. You'll still be able to find the things you put in, but you might as well be using a list.
The phrasing of rule 1 is very important. It is not sufficient to say simply “hash(k1) == hash(k1)”, because that does not take into account the definition of equality of keys. If you are building a hash table with case-insensitive, case-preserving string keys, then “HELLO” and “hello” need to hash to the same value. In fact, “hash(k1) == hash(k1)” is not even strictly necessary. How could it not be necessary? By reversing rule 1, hash(k1) and hash(k1) can be unequal if k1 != k1, that is, if k1 does not equal itself.
How can that happen? It happens if k1 is the floating-point value NaN (not-a-number), which by convention is not equal to anything, not even itself.
Okay, but why bother? Well, remember rule 2. Since NaN != NaN, it should be likely that hash(NaN) != hash(NaN), or else the hash table will have bad performance. This is very strange: the same input is hashed twice, and we're supposed to (at least be likely to) return different hash values. Since the inputs are identical, we need a source of external entropy, like rand.
What if you don't? You get hash tables that don't perform very well if someone can manage to trick you into storing things under NaN repeatedly:
$ cat nan.py
#!/usr/bin/python
import timeit
def build(n):
m = {}
for i in range(n):
m[float("nan")] = 1
n = 1
for i in range(20):
print "%6d %10.6f" % (n, timeit.timeit('build('+str(n)+')',
'from __main__ import build', number=1))
n *= 2
$ python nan.py
1 0.000006
2 0.000004
4 0.000004
8 0.000008
16 0.000011
32 0.000028
64 0.000072
128 0.000239
256 0.000840
512 0.003339
1024 0.012612
2048 0.050331
4096 0.200965
8192 1.032596
16384 4.657481
32768 22.758963
65536 91.899054
$
The behavior here is quadratic: double the input size and the run time quadruples. You can run the equivalent Go program on the Go playground. It has the NaN fix and runs in linear time. (On the playground, wall time stands still, but you can see that it's executing in far less than 100s of seconds. Run it locally for actual timing.)
Now, you could argue that putting a NaN in a hash table is a dumb idea, and also that treating NaN != NaN in a hash table is also a dumb idea, and you'd be right on both counts.
But the alternatives are worse:
The most consistent thing to do is to accept the implications of NaN != NaN: m[NaN] = 1 always creates a new hash table element (since the key is unequal to any existing entry), reading m[NaN] never finds any data (same reason), and iterating over the hash table yields each of the inserted NaN entries.
Behaviors surrounding NaN are always surprising, but if NaN != NaN elsewhere, the least surprising thing you can do is make your hash tables respect that. To do that well, it needs to be likely that hash(NaN) != hash(NaN). And you probably already have a custom floating-point hash function so that +0 and −0 are treated as the same value. Go ahead, call rand for NaN.
(Note: this is different from the hash table performance problem that was circulating in December 2011. In that case, the predictability of collisions on ordinary data was solved by making each different table use a randomly chosen hash function; there's no randomness inside the function itself.)
Go言語のVersion 1 がとうとうリリースされました。
http://blog.golang.org/2012/03/go-version-1-is-released.html
The news, if you hadn’t heard. :) It’s a big thing with me because I’ve put so much time into using it—well, mostly playing with it. I do write and maintain some Go programs for work, but most of my time with Go has been spent contributing solutions to Rosetta Code. I’ve contributed hundreds of Go solutions over the last year or so, and Go has been in the top 10 languages there for some time now. Recently I’ve tried to review all of the solutions to update them to Go 1, and I’m happy to announce that they (almost) all work with Go 1 now.
I wish I could announce that it represents a large body of idiomatic Go code, available as reference solutions common programming tasks, but I’m afraid it’s not. Firstly, I’m not sure how idiomatic my code is. I’ve worked mostly in isolation, and my code almost certainly displays my idiosyncrasies as much as it displays accepted idioms. Secondly of course, is the nature of of the RC site, which is more a wonderland than reference library.
Still, I’d like to invite people to come and visit. Browse the existing Go solutions and be amused or enlightened, hopefully both. But then I’d really like to encourage people to make improvements as they can. That’s the nature of a wiki, and as I said, since such a large fraction of the Go code is mine, there is certainly much room for the code to be improved.
Next there is the list of existing RC tasks with no Go solution yet. Most of these are tasks that awkward for me because I don’t have a computer, and can’t freely do things like install software on the computers I do have access to. If you have or can install up-to-date libraries and software on your computer, some of these tasks should be easy! Please browse the list and contribute any solutions you can. A few of them are simply tasks for which I don’t have the knowledge. For example the HTTP task seemed simple enough, but I don’t know enough to do the HTTPS task.
Finally, if you really enjoy the site, consider contributing a new task that you feel really shows off some feature of Go. I’ve added just a few, but probably still be designed are some great tasks illuminating interfaces, concurrency, and the varied capabilities of the Go standard package library.


The image and image/color packages define a number of types: color.Color and color.Model describe colors, image.Point and image.Rectangle describe basic 2-D geometry, and image.Image brings the two concepts together to represent a rectangular grid of colors. A separate article covers image composition with the image/draw package.
Colors and Color Models
Color is an interface that defines the minimal method set of any type that can be considered a color: one that can be converted to red, green, blue and alpha values. The conversion may be lossy, such as converting from CMYK or YCbCr color spaces.
type Color interface {
// RGBA returns the alpha-premultiplied red, green, blue and alpha values
// for the color. Each value ranges within [0, 0xFFFF], but is represented
// by a uint32 so that multiplying by a blend factor up to 0xFFFF will not
// overflow.
RGBA() (r, g, b, a uint32)
} There are three important subtleties about the return values. First, the red, green and blue are alpha-premultiplied: a fully saturated red that is also 25% transparent is represented by RGBA returning a 75% r. Second, the channels have a 16-bit effective range: 100% red is represented by RGBA returning an r of 65535, not 255, so that converting from CMYK or YCbCr is not as lossy. Third, the type returned is uint32, even though the maximum value is 65535, to guarantee that multiplying two values together won't overflow. Such multiplications occur when blending two colors according to an alpha mask from a third color, in the style of Porter and Duff'sclassic algebra:
dstr, dstg, dstb, dsta := dst.RGBA()
srcr, srcg, srcb, srca := src.RGBA()
_, _, _, m := mask.RGBA()
const M = 1<<16 - 1
// The resultant red value is a blend of dstr and srcr, and ranges in [0, M].
// The calculation for green, blue and alpha is similar.
dstr = (dstr*(M-m) + srcr*m) / M
The last line of that code snippet would have been more complicated if we worked with non-alpha-premultiplied colors, which is why Color uses alpha-premultiplied values.
The image/color package also defines a number of concrete types that implement the Color interface. For example, RGBA is a struct that represents the classic "8 bits per channel" color.
type RGBA struct {
R, G, B, A uint8
} Note that the R field of an RGBA is an 8-bit alpha-premultiplied color in the range [0, 255]. RGBA satisfies the Color interface by multiplying that value by 0x101 to generate a 16-bit alpha-premultiplied color in the range [0, 65535]. Similarly, the NRGBA struct type represents an 8-bit non-alpha-premultiplied color, as used by the PNG image format. When manipulating an NRGBA's fields directly, the values are non-alpha-premultiplied, but when calling the RGBA method, the return values are alpha-premultiplied.
A Model is simply something that can convert Colors to other Colors, possibly lossily. For example, the GrayModel can convert any Color to a desaturated Gray. A Palette can convert any Color to one from a limited palette.
type Model interface {
Convert(c Color) Color
} type Palette []Color
Points and Rectangles
A Point is an (x, y) co-ordinate on the integer grid, with axes increasing right and down. It is neither a pixel nor a grid square. A Point has no intrinsic width, height or color, but the visualizations below use a small colored square.
type Point struct {
X, Y int
} 
p := image.Point{2, 1} A Rectangle is an axis-aligned rectangle on the integer grid, defined by its top-left and bottom-right Point. A Rectangle also has no intrinsic color, but the visualizations below outline rectangles with a thin colored line, and call out their Min and Max Points.
type Rectangle struct {
Min, Max Point
} For convenience, image.Rect(x0, y0, x1, y1) is equivalent to image.Rectangle{image.Point{x0, y0}, image.Point{x1, y1}}, but is much easier to type.
A Rectangle is inclusive at the top-left and exclusive at the bottom-right. For a Point p and a Rectangle r, p.In(r) if and only if r.Min.X <= p.X && p.X < r.Max.X, and similarly for Y. This is analagous to how a slice s[i0:i1] is inclusive at the low end and exclusive at the high end. (Unlike arrays and slices, a Rectangle often has a non-zero origin.)

r := image.Rect(2, 1, 5, 5)
// Dx and Dy return a rectangle's width and height.
fmt.Println(r.Dx(), r.Dy(), image.Pt(0, 0).In(r)) // prints 3 4 false
Adding a Point to a Rectangle translates the Rectangle. Points and Rectangles are not restricted to be in the bottom-right quadrant.

r := image.Rect(2, 1, 5, 5).Add(image.Pt(-4, -2))
fmt.Println(r.Dx(), r.Dy(), image.Pt(0, 0).In(r)) // prints 3 4 true
Intersecting two Rectangles yields another Rectangle, which may be empty.

r := image.Rect(0, 0, 4, 3).Intersect(image.Rect(2, 2, 5, 5))
// Size returns a rectangle's width and height, as a Point.
fmt.Printf("%#v\n", r.Size()) // prints image.Point{X:2, Y:1}
Points and Rectangles are passed and returned by value. A function that takes a Rectangle argument will be as efficient as a function that takes two Point arguments, or four int arguments.
Images
An Image maps every grid square in a Rectangle to a Color from a Model. "The pixel at (x, y)" refers to the color of the grid square defined by the points (x, y), (x+1, y), (x+1, y+1) and (x, y+1).
type Image interface {
// ColorModel returns the Image's color model.
ColorModel() color.Model
// Bounds returns the domain for which At can return non-zero color.
// The bounds do not necessarily contain the point (0, 0).
Bounds() Rectangle
// At returns the color of the pixel at (x, y).
// At(Bounds().Min.X, Bounds().Min.Y) returns the upper-left pixel of the grid.
// At(Bounds().Max.X-1, Bounds().Max.Y-1) returns the lower-right one.
At(x, y int) color.Color
} A common mistake is assuming that an Image's bounds start at (0, 0). For example, an animated GIF contains a sequence of Images, and each Image after the first typically only holds pixel data for the area that changed, and that area doesn't necessarily start at (0, 0). The correct way to iterate over an Image m's pixels looks like:
b := m.Bounds()
for y := b.Min.Y; y < b.Max.Y; y++ {
for x := b.Min.X; y < b.Max.X; x++ {
doStuffWith(m.At(x, y))
}
}
Image implementations do not have to be based on an in-memory slice of pixel data. For example, a Uniform is an Image of enormous bounds and uniform color, whose in-memory representation is simply that color.
type Uniform struct {
C color.Color
} Typically, though, programs will want an image based on a slice. Struct types like RGBA and Gray (which other packages refer to as image.RGBA and image.Gray) hold slices of pixel data and implement the Image interface.
type RGBA struct {
// Pix holds the image's pixels, in R, G, B, A order. The pixel at
// (x, y) starts at Pix[(y-Rect.Min.Y)*Stride + (x-Rect.Min.X)*4].
Pix []uint8
// Stride is the Pix stride (in bytes) between vertically adjacent pixels.
Stride int
// Rect is the image's bounds.
Rect Rectangle
} These types also provide a Set(x, y int, c color.Color) method that allows modifying the image one pixel at a time.
m := image.NewRGBA(image.Rect(0, 0, 640, 480))
m.Set(5, 5, color.RGBA{255, 0, 0, 255})
If you're reading or writing a lot of pixel data, it can be more efficient, but more complicated, to access these struct type's Pix field directly.
The slice-based Image implementations also provide a SubImage method, which returns an Image backed by the same array. Modifying the pixels of a sub-image will affect the pixels of the original image, analagous to how modifying the contents of a sub-slice s[i0:i1] will affect the contents of the original slice s.

m0 := image.NewRGBA(image.Rect(0, 0, 8, 5))
m1 := m0.SubImage(image.Rect(1, 2, 5, 5)).(*image.RGBA)
fmt.Println(m0.Bounds().Dx(), m1.Bounds().Dx()) // prints 8, 4
fmt.Println(m0.Stride == m1.Stride) // prints true
For low-level code that works on an image's Pix field, be aware that ranging over Pix can affect pixels outside an image's bounds. In the example above, the pixels covered by m1.Pix are shaded in blue. Higher-level code, such as the At and Setmethods or the image/draw package, will clip their operations to the image's bounds.
Image Formats
The standard package library supports a number of common image formats, such as GIF, JPEG and PNG. If you know the format of a source image file, you can decode from an io.Reader directly.
import (
"image/jpeg"
"image/png"
"io"
)
// convertJPEGToPNG converts from JPEG to PNG.
func convertJPEGToPNG(w io.Writer, r io.Reader) error {
img, err := jpeg.Decode(r)
if err != nil {
return err
}
return png.Encode(w, img)
}
If you have image data of unknown format, the image.Decode function can detect the format. The set of recognized formats is constructed at run time and is not limited to those in the standard package library. An image format package typically registers its format in an init function, and the main package will "underscore import" such a package solely for the side effect of format registration.
import (
"image"
"image/png"
"io"
_ "code.google.com/p/vp8-go/webp"
_ "image/jpeg"
)
// convertToPNG converts from any recognized format to PNG.
func convertToPNG(w io.Writer, r io.Reader) error {
img, _, err := image.Decode(r)
if err != nil {
return err
}
return png.Encode(w, img)
}
Package image/draw defines only one operation: drawing a source image onto a destination image, through an optional mask image. This one operation is surprisingly versatile and can perform a number of common image manipulation tasks elegantly and efficiently.
Composition is performed pixel by pixel in the style of the Plan 9 graphics library and the X Render extension. The model is based on the classic "Compositing Digital Images" paper by Porter and Duff, with an additional mask parameter: dst = (src IN mask) OP dst. For a fully opaque mask, this reduces to the original Porter-Duff formula: dst = src OP dst. In Go, a nil mask image is equivalent to an infinitely sized, fully opaque mask image.
The Porter-Duff paper presented 12 different composition operators, but with an explicit mask, only 2 of these are needed in practice: source-over-destination and source. In Go, these operators are represented by the Over and Src constants. The Over operator performs the natural layering of a source image over a destination image: the change to the destination image is smaller where the source (after masking) is more transparent (that is, has lower alpha). The Src operator merely copies the source (after masking) with no regard for the destination image's original content. For fully opaque source and mask images, the two operators produce the same output, but the Src operator is usually faster.
Geometric Alignment
Composition requires associating destination pixels with source and mask pixels. Obviously, this requires destination, source and mask images, and a composition operator, but it also requires specifying what rectangle of each image to use. Not every drawing should write to the entire destination: when updating an animating image, it is more efficient to only draw the parts of the image that have changed. Not every drawing should read from the entire source: when using a sprite that combines many small images into one large one, only a part of the image is needed. Not every drawing should read from the entire mask: a mask image that collects a font's glyphs is similar to a sprite. Thus, drawing also needs to know three rectangles, one for each image. Since each rectangle has the same width and height, it suffices to pass a destination rectangle `r` and two points sp and mp: the source rectangle is equal to rtranslated so that r.Min in the destination image aligns with sp in the source image, and similarly for mp. The effective rectangle is also clipped to each image's bounds in their respective co-ordinate space.

The DrawMaskfunction takes seven arguments, but an explicit mask and mask-point are usually unnecessary, so the Draw function takes five:
// Draw calls DrawMask with a nil mask.
func Draw(dst Image, r image.Rectangle, src image.Image, sp image.Point, op Op)
func DrawMask(dst Image, r image.Rectangle, src image.Image, sp image.Point,
mask image.Image, mp image.Point, op Op)
The destination image must be mutable, so the image/draw package defines a draw.Imageinterface which has a Set method.
type Image interface {
image.Image
Set(x, y int, c color.Color)
} Filling a Rectangle
To fill a rectangle with a solid color, use an image.Uniformsource. The ColorImage type re-interprets a Color as a practically infinite-sized Image of that color. For those familiar with the design of Plan 9's draw library, there is no need for an explicit "repeat bit" in Go's slice-based image types; the concept is subsumed by Uniform.
// image.ZP is the zero point -- the origin.
draw.Draw(dst, r, &image.Uniform{c}, image.ZP, draw.Src)
To initialize a new image to all-blue:
m := image.NewRGBA(image.Rect(0, 0, 640, 480))
blue := color.RGBA{0, 0, 255, 255}
draw.Draw(m, m.Bounds(), &image.Uniform{blue}, image.ZP, draw.Src)
To reset an image to transparent (or black, if the destination image's color model cannot represent transparency), use image.Transparent, which is an image.Uniform:
draw.Draw(m, m.Bounds(), image.Transparent, image.ZP, draw.Src)

Copying an Image
To copy from a rectangle sr in the source image to a rectangle starting at a point dp in the destination, convert the source rectangle into the destination image's co-ordinate space:
r := image.Rectangle{dp, dp.Add(sr.Size())}
draw.Draw(dst, r, src, sr.Min, draw.Src) Alternatively:
r := sr.Sub(sr.Min).Add(dp)
draw.Draw(dst, r, src, sr.Min, draw.Src)
To copy the entire source image, use sr = src.Bounds().

Scrolling an Image
Scrolling an image is just copying an image to itself, with different destination and source rectangles. Overlapping destination and source images are perfectly valid, just as Go's built-in copy function can handle overlapping destination and source slices. To scroll an image m by 20 pixels:
b := m.Bounds()
p := image.Pt(0, 20)
// Note that even though the second argument is b,
// the effective rectangle is smaller due to clipping.
draw.Draw(m, b, m, b.Min.Add(p), draw.Src)
dirtyRect := b.Intersect(image.Rect(b.Min.X, b.Max.Y-20, b.Max.X, b.Max.Y))

Converting an Image to RGBA
The result of decoding an image format might not be an image.RGBA: decoding a GIF results in an image.Paletted, decoding a JPEG results in a ycbcr.YCbCr, and the result of decoding a PNG depends on the image data. To convert any image to an image.RGBA:
b := src.Bounds()
m := image.NewRGBA(image.Rect(0, 0, b.Dx(), b.Dy()))
draw.Draw(m, m.Bounds(), src, b.Min, draw.Src)

Drawing Through a Mask
To draw an image through a circular mask with center p and radius r:
type circle struct {
p image.Point
r int
}
func (c *circle) ColorModel() color.Model {
return color.AlphaModel
}
func (c *circle) Bounds() image.Rectangle {
return image.Rect(c.p.X-c.r, c.p.Y-c.r, c.p.X+c.r, c.p.Y+c.r)
}
func (c *circle) At(x, y int) color.Color {
xx, yy, rr := float64(x-c.p.X)+0.5, float64(y-c.p.Y)+0.5, float64(c.r)
if xx*xx+yy*yy < rr*rr {
return color.Alpha{255}
}
return color.Alpha{0}
} draw.DrawMask(dst, dst.Bounds(), src, image.ZP, &circle{p, r}, image.ZP, draw.Over) 
Drawing Font Glyphs
To draw a font glyph in blue starting from a point p, draw with an image.ColorImage source and an image.Alpha mask. For simplicity, we aren't performing any sub-pixel positioning or rendering, or correcting for a font's height above a baseline.
src := &image.Uniform{color.RGBA{0, 0, 255, 255}}
mask := theGlyphImageForAFont()
mr := theBoundsFor(glyphIndex)
draw.DrawMask(dst, mr.Sub(mr.Min).Add(p), src, image.ZP, mask, mr.Min, draw.Over) 
Performance
The image/draw package implementation demonstrates how to provide an image manipulation function that is both general purpose, yet efficient for common cases. The DrawMask function takes arguments of interface types, but immediately makes type assertions that its arguments are of specific struct types, corresponding to common operations like drawing one image.RGBA image onto another, or drawing an image.Alpha mask (such as a font glyph) onto an image.RGBA image. If a type assertion succeeds, that type information is used to run a specialized implementation of the general algorithm. If the assertions fail, the fallback code path uses the generic At and Set methods. The fast-paths are purely a performance optimization; the resultant destination image is the same either way. In practice, only a small number of special cases are necessary to support typical applications.
The Go project takes documentation seriously. Documentation is a huge part of making software accessible and maintainable. Of course it must be well-written and accurate, but it also must be easy to write and to maintain. Ideally, it should be coupled to the code itself so the documentation evolves along with the code. The easier it is for programmers to produce good documentation, the better for everyone.
To that end, we have developed the godoc documentation tool. This article describes godoc's approach to documentation, and explains how you can use our conventions and tools to write good documentation for your own projects.
Godoc parses Go source code - including comments - and produces documentation as HTML or plain text. The end result is documentation tightly coupled with the code it documents. For example, through godoc's web interface you can navigate from a function's documentation to its implementation with one click.
Godoc is conceptually related to Python's Docstring and Java's Javadoc, but its design is simpler. The comments read by godoc are not language constructs (as with Docstring) nor must they have their own machine-readable syntax (as with Javadoc). Godoc comments are just good comments, the sort you would want to read even if godoc didn't exist.
The convention is simple: to document a type, variable, constant, function, or even a package, write a regular comment directly preceding its declaration, with no intervening blank line. Godoc will then present that comment as text alongside the item it documents. For example, this is the documentation for the fmt package's Fprintfunction:
// Fprint formats using the default formats for its operands and writes to w.
// Spaces are added between operands when neither is a string.
// It returns the number of bytes written and any write error encountered.
func Fprint(w io.Writer, a ...interface{}) (n int, err error) {
Notice this comment is a complete sentence that begins with the name of the element it describes. This important convention allows us to generate documentation in a variety of formats, from plain text to HTML to UNIX man pages, and makes it read better when tools truncate it for brevity, such as when they extract the first line or sentence.
Comments on package declarations should provide general package documentation. These comments can be short, like the sortpackage's brief description:
// Package sort provides primitives for sorting slices and user-defined
// collections.
package sort
They can also be detailed like the gob package's overview. That package uses another convention for packages that need large amounts of introductory documentation: the package comment is placed in its own file, doc.go, which contains only those comments and a package clause.
When writing package comments of any size, keep in mind that their first sentence will appear in godoc's package list.
Comments that are not adjacent to a top-level declaration are omitted from godoc's output, with one notable exception. Top-level comments that begin with the word "BUG(who)” are recognized as known bugs, and included in the "Bugs” section of the package documentation. The "who” part should be the user name of someone who could provide more information. For example, this is a known issue from the bytes package:
// BUG(r): The rule Title uses for word boundaries does not handle Unicode punctuation properly.
Godoc treats executable commands somewhat differently. Instead of inspecting the command source code, it looks for a Go source file belonging to the special package "documentation”. The comment on the "package documentation” clause is used as the command's documentation. For example, see the godoc documentation and its corresponding doc.go file.
There are a few formatting rules that Godoc uses when converting comments to HTML:
Note that none of these rules requires you to do anything out of the ordinary.
In fact, the best thing about godoc's minimal approach is how easy it is to use. As a result, a lot of Go code, including all of the standard library, already follows the conventions.
Your own code can present good documentation just by having comments as described above. Any Go packages installed inside $GOROOT/src/pkgand any GOPATH work spaces will already be accessible via godoc's command-line and HTTP interfaces, and you can specify additional paths for indexing via the -path flag or just by running "godoc ."in the source directory. See the godoc documentationfor more details.
Reflection in computing is the ability of a program to examine its own structure, particularly through types; it's a form of metaprogramming. It's also a great source of confusion.
In this article we attempt to clarify things by explaining how reflection works in Go. Each language's reflection model is different (and many languages don't support it at all), but this article is about Go, so for the rest of this article the word "reflection" should be taken to mean "reflection in Go".
Types and interfaces
Because reflection builds on the type system, let's start with a refresher about types in Go.
Go is statically typed. Every variable has a static type, that is, exactly one type known and fixed at compile time: int, float32, *MyType, []byte, and so on. If we declare
type MyInt int
var i int
var j MyInt
then i has type int and jhas type MyInt. The variables i and j have distinct static types and, although they have the same underlying type, they cannot be assigned to one another without a conversion.
One important category of type is interface types, which represent fixed sets of methods. An interface variable can store any concrete (non-interface) value as long as that value implements the interface's methods. A well-known pair of examples is io.Reader and io.Writer, the types Reader and Writer from the io package:
// Reader is the interface that wraps the basic Read method.
type Reader interface {
Read(p []byte) (n int, err error)
}
// Writer is the interface that wraps the basic Write method.
type Writer interface {
Write(p []byte) (n int, err error)
}
Any type that implements a Read (or Write) method with this signature is said to implement io.Reader (or io.Writer). For the purposes of this discussion, that means that a variable of type io.Reader can hold any value whose type has a Read method:
var r io.Reader
r = os.Stdin
r = bufio.NewReader(r)
r = new(bytes.Buffer)
// and so on
It's important to be clear that whatever concrete value r may hold, r's type is always io.Reader: Go is statically typed and the static type of r is io.Reader.
An extremely important example of an interface type is the empty interface:
interface{}
It represents the empty set of methods and is satisfied by any value at all, since any value has zero or more methods.
Some people say that Go's interfaces are dynamically typed, but that is misleading. They are statically typed: a variable of interface type always has the same static type, and even though at run time the value stored in the interface variable may change type, that value will always satisfy the interface.
We need to be precise about all this because reflection and interfaces are closely related.
The representation of an interface
Russ Cox has written a detailed blog post about the representation of interface values in Go. It's not necessary to repeat the full story here, but a simplified summary is in order.
A variable of interface type stores a pair: the concrete value assigned to the variable, and that value's type descriptor. To be more precise, the value is the underlying concrete data item that implements the interface and the type describes the full type of that item. For instance, after
var r io.Reader
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
return nil, err
}
r = tty
r contains, schematically, the (value, type) pair, (tty, *os.File). Notice that the type *os.File implements methods other than Read; even though the interface value provides access only to the Read method, the value inside carries all the type information about that value. That's why we can do things like this:
var w io.Writer
w = r.(io.Writer)
The expression in this assignment is a type assertion; what it asserts is that the item inside r also implements io.Writer, and so we can assign it to w. After the assignment, w will contain the pair (tty, *os.File). That's the same pair as was held in r. The static type of the interface determines what methods may be invoked with an interface variable, even though the concrete value inside may have a larger set of methods.
Continuing, we can do this:
var empty interface{}
empty = w and our empty interface value e will again contain that same pair, (tty, *os.File). That's handy: an empty interface can hold any value and contains all the information we could ever need about that value.
(We don't need a type assertion here because it's known statically that w satisfies the empty interface. In the example where we moved a value from a Reader to a Writer, we needed to be explicit and use a type assertion because Writer's methods are not a subset of Reader's.)
One important detail is that the pair inside an interface always has the form (value, concrete type) and cannot have the form (value, interface type). Interfaces do not hold interface values.
Now we're ready to reflect.
The first law of reflection
1. Reflection goes from interface value to reflection object.
At the basic level, reflection is just a mechanism to examine the type and value pair stored inside an interface variable. To get started, there are two types we need to know about in package reflect: Type and Value. Those two types give access to the contents of an interface variable, and two simple functions, called reflect.TypeOf and reflect.ValueOf, retrieve reflect.Typeand reflect.Value pieces out of an interface value. (Also, from the reflect.Value it's easy to get to the reflect.Type, but let's keep the Value and Type concepts separate for now.)
Let's start with TypeOf:
package main
import (
"fmt"
"reflect"
)
func main() {
var x float64 = 3.4
fmt.Println("type:", reflect.TypeOf(x))
}
This program prints
type: float64
You might be wondering where the interface is here, since the program looks like it's passing the float64variable x, not an interface value, to reflect.TypeOf. But it's there; as godoc reports, the signature of reflect.TypeOf includes an empty interface:
// TypeOf returns the reflection Type of the value in the interface{}.
func TypeOf(i interface{}) Type
When we call reflect.TypeOf(x), x is first stored in an empty interface, which is then passed as the argument; reflect.TypeOf unpacks that empty interface to recover the type information.
The reflect.ValueOf function, of course, recovers the value (from here on we'll elide the boilerplate and focus just on the executable code):
var x float64 = 3.4
fmt.Println("value:", reflect.ValueOf(x))
prints
value: <float64 Value>
Both reflect.Type and reflect.Value have lots of methods to let us examine and manipulate them. One important example is that Value has a Type method that returns the Type of a reflect.Value. Another is that both Typeand Value have a Kind method that returns a constant indicating what sort of item is stored: Uint, Float64, Slice, and so on. Also methods on Value with names like Int and Float let us grab values (as int64 and float64) stored inside:
var x float64 = 3.4
v := reflect.ValueOf(x)
fmt.Println("type:", v.Type())
fmt.Println("kind is float64:", v.Kind() == reflect.Float64)
fmt.Println("value:", v.Float())
prints
type: float64
kind is float64: true
value: 3.4
There are also methods like SetInt and SetFloat but to use them we need to understand settability, the subject of the third law of reflection, discussed below.
The reflection library has a couple of properties worth singling out. First, to keep the API simple, the "getter" and "setter" methods of Value operate on the largest type that can hold the value: int64 for all the signed integers, for instance. That is, the Int method of Value returns an int64 and the SetInt value takes an int64; it may be necessary to convert to the actual type involved:
var x uint8 = 'x'
v := reflect.ValueOf(x)
fmt.Println("type:", v.Type()) // uint8.
fmt.Println("kind is uint8: ", v.Kind() == reflect.Uint8) // true.
x = uint8(v.Uint()) // v.Uint returns a uint64.
The second property is that the Kind of a reflection object describes the underlying type, not the static type. If a reflection object contains a value of a user-defined integer type, as in
type MyInt int
var x MyInt = 7
v := reflect.ValueOf(x)
the Kind of v is still reflect.Int, even though the static type of x is MyInt, not int. In other words, the Kind cannot discriminate an int from a MyInt even though the Type can.
The second law of reflection
2. Reflection goes from reflection object to interface value.
Like physical reflection, reflection in Go generates its own inverse.
Given a reflect.Value we can recover an interface value using the Interface method; in effect the method packs the type and value information back into an interface representation and returns the result:
// Interface returns v's value as an interface{}.
func (v Value) Interface() interface{}
As a consequence we can say
y := v.Interface().(float64) // y will have type float64.
fmt.Println(y)
to print the float64 value represented by the reflection object v.
We can do even better, though. The arguments to fmt.Println, fmt.Printf and so on are all passed as empty interface values, which are then unpacked by the fmt package internally just as we have been doing in the previous examples. Therefore all it takes to print the contents of a reflect.Value correctly is to pass the result of the Interface method to the formatted print routine:
fmt.Println(v.Interface())
(Why not fmt.Println(v)? Because v is a reflect.Value; we want the concrete value it holds.) Since our value is a float64, we can even use a floating-point format if we want:
fmt.Printf("value is %7.1e\n", v.Interface()) and get in this case
3.4e+00
Again, there's no need to type-assert the result of v.Interface() to float64; the empty interface value has the concrete value's type information inside and Printf will recover it.
In short, the Interface method is the inverse of the ValueOf function, except that its result is always of static type interface{}.
Reiterating: Reflection goes from interface values to reflection objects and back again.
The third law of reflection
3. To modify a reflection object, the value must be settable.
The third law is the most subtle and confusing, but it's easy enough to understand if we start from first principles.
Here is some code that does not work, but is worth studying.
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(7.1) // Error: will panic.
If you run this code, it will panic with the cryptic message
panic: reflect.Value.SetFloat using unaddressable value
The problem is not that the value 7.1 is not addressable; it's that v is not settable. Settability is a property of a reflection Value, and not all reflection Values have it.
The CanSet method of Value reports the settability of a Value; in our case,
var x float64 = 3.4
v := reflect.ValueOf(x)
fmt.Println("settability of v:", v.CanSet())
prints
settability of v: false
It is an error to call a Set method on an non-settable Value. But what is settability?
Settability is a bit like addressability, but stricter. It's the property that a reflection object can modify the actual storage that was used to create the reflection object. Settability is determined by whether the reflection object holds the original item. When we say
var x float64 = 3.4
v := reflect.ValueOf(x)
we pass a copy of x to reflect.ValueOf, so the interface value created as the argument to reflect.ValueOf is a copy of x, not x itself. Thus, if the statement
v.SetFloat(7.1)
were allowed to succeed, it would not update x, even though v looks like it was created from x. Instead, it would update the copy of xstored inside the reflection value and x itself would be unaffected. That would be confusing and useless, so it is illegal, and settability is the property used to avoid this issue.
If this seems bizarre, it's not. It's actually a familiar situation in unusual garb. Think of passing x to a function:
f(x)
We would not expect f to be able to modify x because we passed a copy of x's value, not x itself. If we want f to modify x directly we must pass our function the address of x (that is, a pointer to x):
f(&x)
This is straightforward and familiar, and reflection works the same way. If we want to modify x by reflection, we must give the reflection library a pointer to the value we want to modify.
Let's do that. First we initialize x as usual and then create a reflection value that points to it, called p.
var x float64 = 3.4
p := reflect.ValueOf(&x) // Note: take the address of x.
fmt.Println("type of p:", p.Type())
fmt.Println("settability of p:", p.CanSet())
The output so far is
type of p: *float64
settability of p: false
The reflection object p isn't settable, but it's not p we want to set, it's (in effect) *p. To get to what p points to, we call the Elemmethod of Value, which indirects through the pointer, and save the result in a reflection Value called v:
v := p.Elem()
fmt.Println("settability of v:", v.CanSet())
Now v is a settable reflection object, as the output demonstrates,
settability of v: true
and since it represents x, we are finally able to use v.SetFloat to modify the value of x:
v.SetFloat(7.1)
fmt.Println(v.Interface())
fmt.Println(x)
The output, as expected, is
7.1
7.1
Reflection can be hard to understand but it's doing exactly what the language does, albeit through reflection Types and Values that can disguise what's going on. Just keep in mind that reflection Values need the address of something in order to modify what they represent.
Structs
In our previous example v wasn't a pointer itself, it was just derived from one. A common way for this situation to arise is when using reflection to modify the fields of a structure. As long as we have the address of the structure, we can modify its fields.
Here's a simple example that analyzes a struct value, t. We create the reflection object with the address of the struct because we'll want to modify it later. Then we set typeOfT to its type and iterate over the fields using straightforward method calls (see package reflect for details). Note that we extract the names of the fields from the struct type, but the fields themselves are regular reflect.Valueobjects.
type T struct {
A int
B string
}
t := T{23, "skidoo"}
s := reflect.ValueOf(&t).Elem()
typeOfT := s.Type()
for i := 0; i < s.NumField(); i++ {
f := s.Field(i)
fmt.Printf("%d: %s %s = %v\n", i,
typeOfT.Field(i).Name, f.Type(), f.Interface())
} The output of this program is
0: A int = 23
1: B string = skidoo
There's one more point about settability introduced in passing here: the field names of T are upper case (exported) because only exported fields of a struct are settable.
Because s contains a settable reflection object, we can modify the fields of the structure.
s.Field(0).SetInt(77)
s.Field(1).SetString("Sunset Strip")
fmt.Println("t is now", t)
And here's the result:
t is now {77 Sunset Strip}
If we modified the program so that s was created from t, not &t, the calls to SetInt and SetString would fail as the fields of t would not be settable.
Conclusion
Here again are the laws of reflection:
Once you understand these laws reflection in Go becomes much easier to use, although it remains subtle. It's a powerful tool that should be used with care and avoided unless strictly necessary.
There's plenty more to reflection that we haven't covered — sending and receiving on channels, allocating memory, using slices and maps, calling methods and functions — but this post is long enough. We'll cover some of those topics in a later article.
To transmit a data structure across a network or to store it in a file, it mustbe encoded and then decoded again. There are many encodings available, ofcourse: JSON,XML, Google'sprotocol buffers, and more.And now there's another, provided by Go's gobpackage.
Why define a new encoding? It's a lot of work and redundant at that. Why notjust use one of the existing formats? Well, for one thing, we do! Go haspackages supporting all the encodings just mentioned (theprotocol buffer package is ina separate repository but it's one of the most frequently downloaded). And formany purposes, including communicating with tools and systems written in otherlanguages, they're the right choice.
But for a Go-specific environment, such as communicating between two serverswritten in Go, there's an opportunity to build something much easier to use andpossibly more efficient.
Gobs work with the language in a way that an externally-defined,language-independent encoding cannot. At the same time, there are lessons to belearned from the existing systems.
Goals
The gob package was designed with a number of goals in mind.
First, and most obvious, it had to be very easy to use. First, because Go hasreflection, there is no need for a separate interface definition language or"protocol compiler". The data structure itself is all the package should needto figure out how to encode and decode it. On the other hand, this approachmeans that gobs will never work as well with other languages, but that's OK:gobs are unashamedly Go-centric.
Efficiency is also important. Textual representations, exemplified by XML andJSON, are too slow to put at the center of an efficient communications network.A binary encoding is necessary.
Gob streams must be self-describing. Each gob stream, read from the beginning,contains sufficient information that the entire stream can be parsed by anagent that knows nothing a priori about its contents. This property means thatyou will always be able to decode a gob stream stored in a file, even longafter you've forgotten what data it represents.
There were also some things to learn from our experiences with Google protocolbuffers.
Protocol buffer misfeatures
Protocol buffers had a major effect on the design of gobs, but have threefeatures that were deliberately avoided. (Leaving aside the property thatprotocol buffers aren't self-describing: if you don't know the data definitionused to encode a protocol buffer, you might not be able to parse it.)
First, protocol buffers only work on the data type we call a struct in Go. Youcan't encode an integer or array at the top level, only a struct with fieldsinside it. That seems a pointless restriction, at least in Go. If all you wantto send is an array of integers, why should you have to put it into astruct first?
Next, a protocol buffer definition may specify that fields T.x andT.y are required to be present whenever a value of typeT is encoded or decoded. Although such required fields may seemlike a good idea, they are costly to implement because the codec must maintain aseparate data structure while encoding and decoding, to be able to report whenrequired fields are missing. They're also a maintenance problem. Over time, onemay want to modify the data definition to remove a required field, but that maycause existing clients of the data to crash. It's better not to have them in theencoding at all. (Protocol buffers also have optional fields. But if we don'thave required fields, all fields are optional and that's that. There will bemore to say about optional fields a little later.)
The third protocol buffer misfeature is default values. If a protocol bufferomits the value for a "defaulted" field, then the decoded structure behaves asif the field were set to that value. This idea works nicely when you havegetter and setter methods to control access to the field, but is harder tohandle cleanly when the container is just a plain idiomatic struct. Requiredfields are also tricky to implement: where does one define the default values,what types do they have (is text UTF-8? uninterpreted bytes? how many bits in afloat?) and despite the apparent simplicity, there were a number ofcomplications in their design and implementation for protocol buffers. Wedecided to leave them out of gobs and fall back to Go's trivial but effectivedefaulting rule: unless you set something otherwise, it has the "zero value"for that type - and it doesn't need to be transmitted.
So gobs end up looking like a sort of generalized, simplified protocol buffer.How do they work?
Values
The encoded gob data isn't about int8s and uint16s.Instead, somewhat analogous to constants in Go, its integer values are abstract,sizeless numbers, either signed or unsigned. When you encode anint8, its value is transmitted as an unsized, variable-lengthinteger. When you encode an int64, its value is also transmitted asan unsized, variable-length integer. (Signed and unsigned are treateddistinctly, but the same unsized-ness applies to unsigned values too.) If bothhave the value 7, the bits sent on the wire will be identical. When the receiverdecodes that value, it puts it into the receiver's variable, which may be ofarbitrary integer type. Thus an encoder may send a 7 that came from anint8, but the receiver may store it in an int64. Thisis fine: the value is an integer and as a long as it fits, everything works. (Ifit doesn't fit, an error results.) This decoupling from the size of the variablegives some flexibility to the encoding: we can expand the type of the integervariable as the software evolves, but still be able to decode old data.
This flexibility also applies to pointers. Before transmission, all pointers areflattened. Values of type int8, *int8,**int8, ****int8, etc. are all transmitted as aninteger value, which may then be stored in int of any size, or*int, or ******int, etc. Again, this allows forflexibility.
Flexibility also happens because, when decoding a struct, only those fieldsthat are sent by the encoder are stored in the destination. Given the value
type T struct{ X, Y, Z int } // Only exported fields are encoded and decoded.
var t = T{X: 7, Y: 0, Z: 8}the encoding of t sends only the 7 and 8. Because it's zero, thevalue of Y isn't even sent; there's no need to send a zero value.
The receiver could instead decode the value into this structure:
type U struct{ X, Y *int8 } // Note: pointers to int8s
var u Uand acquire a value of u with only X set (to theaddress of an int8 variable set to 7); the Z field isignored - where would you put it? When decoding structs, fields are matched byname and compatible type, and only fields that exist in both are affected. Thissimple approach finesses the "optional field" problem: as the typeT evolves by adding fields, out of date receivers will stillfunction with the part of the type they recognize. Thus gobs provide theimportant result of optional fields - extensibility - without any additionalmechanism or notation.
From integers we can build all the other types: bytes, strings, arrays, slices,maps, even floats. Floating-point values are represented by their IEEE 754floating-point bit pattern, stored as an integer, which works fine as long asyou know their type, which we always do. By the way, that integer is sent inbyte-reversed order because common values of floating-point numbers, such assmall integers, have a lot of zeros at the low end that we can avoidtransmitting.
One nice feature of gobs that Go makes possible is that they allow you to defineyour own encoding by having your type satisfy theGobEncoder andGobDecoder interfaces, in a manneranalogous to the JSON package'sMarshaler andUnmarshaler and also to theStringer interface frompackage fmt. This facility makes it possible torepresent special features, enforce constraints, or hide secrets when youtransmit data. See the documentation fordetails.
Types on the wire
The first time you send a given type, the gob package includes in the datastream a description of that type. In fact, what happens is that the encoder isused to encode, in the standard gob encoding format, an internal struct thatdescribes the type and gives it a unique number. (Basic types, plus the layoutof the type description structure, are predefined by the software forbootstrapping.) After the type is described, it can be referenced by its typenumber.
Thus when we send our first type T, the gob encoder sends adescription of T and tags it with a type number, say 127. Allvalues, including the first, are then prefixed by that number, so a stream ofT values looks like:
("define type id" 127, definition of type T)(127, T value)(127, T value), ...
These type numbers make it possible to describe recursive types and send valuesof those types. Thus gobs can encode types such as trees:
type Node struct {
Value int
Left, Right *Node
}(It's an exercise for the reader to discover how the zero-defaulting rule makesthis work, even though gobs don't represent pointers.)
With the type information, a gob stream is fully self-describing except for theset of bootstrap types, which is a well-defined starting point.
Compiling a machine
The first time you encode a value of a given type, the gob package builds alittle interpreted machine specific to that data type. It uses reflection onthe type to construct that machine, but once the machine is built it does notdepend on reflection. The machine uses package unsafe and some trickery toconvert the data into the encoded bytes at high speed. It could use reflectionand avoid unsafe, but would be significantly slower. (A similar high-speedapproach is taken by the protocol buffer support for Go, whose design wasinfluenced by the implementation of gobs.) Subsequent values of the same typeuse the already-compiled machine, so they can be encoded right away.
Decoding is similar but harder. When you decode a value, the gob package holdsa byte slice representing a value of a given encoder-defined type to decode,plus a Go value into which to decode it. The gob package builds a machine forthat pair: the gob type sent on the wire crossed with the Go type provided fordecoding. Once that decoding machine is built, though, it's again areflectionless engine that uses unsafe methods to get maximum speed.
Use
There's a lot going on under the hood, but the result is an efficient,easy-to-use encoding system for transmitting data. Here's a complete exampleshowing differing encoded and decoded types. Note how easy it is to send andreceive values; all you need to do is present values and variables to thegob package and it does all the work.
package main
import (
"bytes"
"encoding/gob"
"fmt"
"log"
)
type P struct {
X, Y, Z int
Name string
}
type Q struct {
X, Y *int32
Name string
}
func main() {
// Initialize the encoder and decoder. Normally enc and dec would be
// bound to network connections and the encoder and decoder would
// run in different processes.
var network bytes.Buffer // Stand-in for a network connection
enc := gob.NewEncoder(&network) // Will write to network.
dec := gob.NewDecoder(&network) // Will read from network.
// Encode (send) the value.
err := enc.Encode(P{3, 4, 5, "Pythagoras"})
if err != nil {
log.Fatal("encode error:", err)
}
// Decode (receive) the value.
var q Q
err = dec.Decode(&q)
if err != nil {
log.Fatal("decode error:", err)
}
fmt.Printf("%q: {%d,%d}\n", q.Name, *q.X, *q.Y)
}
You can compile and run this example code in theGo Playground.
The rpc package builds on gobs to turn thisencode/decode automation into transport for method calls across the network.That's a subject for another article.
Details
The gob package documentation, especially thefile doc.go, expands on many of thedetails described here and includes a full worked example showing how theencoding represents data. If you are interested in the innards of the gobimplementation, that's a good place to start.


After yesterday's post that advocated using RSA public exponents of 3 or 216+1 in DNSSEC for performance, Dan Kaminsky asked me whether there was a potential DoS vector by using really big public exponents.
Recall that the RSA signature verification core is me mod n. By making e and n larger, we can make the operation slower. But there are limits, at least in OpenSSL:
/* for large moduli, enforce exponent limit */
if (BN_num_bits(rsa->n) > OPENSSL_RSA_SMALL_MODULUS_BITS) {
if (BN_num_bits(rsa->e) > OPENSSL_RSA_MAX_PUBEXP_BITS) {
RSAerr(RSA_F_RSA_EAY_PUBLIC_ENCRYPT, RSA_R_BAD_E_VALUE);
return -1;
}
}
So, if n is large, we enforce a limit on e. The values of the #defines are such that for n>3072 bits, e must be less than or equal to 64 bits. So the slowest operations happen with an n and e of 3072 bits. (The fact that e<n is enforced earlier in the code.)
So I setup *.bige.imperialviolet.org. This is a perfectly valid and well signed zone which happens to use a 3072-bit key with a 3072-bit public exponent. (I could probably have slowed things down more by picking a public exponent with lots of 1s in its binary representation, but it's just a random number in this case.) One can resolve records 1.bige.imperialviolet.org, 2.bige.imperialviolet.org, … and the server doesn't have to sign anything because it's a wildcard: a single signature covers all of the names. However, the resolver validates the signature every time.
On my 2.66GHz, Core 2 laptop, 15 requests per second causes unbound to take 95% of a core. A couple hundred queries per second would probably put most DNSSEC resolvers in serious trouble.
So I'd recommend limiting the public exponent size in DNSSEC to 216+1, except that people are already mistakenly using 232+1, so I guess that needs to be the limit. The DNSSEC spec limits the modulus size to 4096-bits, and 4096-bit signatures are about 13 times slower to verify than the typical 1024-bit signatures used in DNSSEC. But that's a lot less of a DoS vector than bige.imperialviolet.org, which is 2230 times slower than normal.
RSA public operations are much faster than private operations. Thirty-two times faster for a 2048-bit key on my machine. But the two operations are basically the same: take the message, raise it to the power of the public or private exponent and reduce modulo the key's modulus.
What makes the public operations so much faster is that the public exponent is typically tiny, while the private exponent should be the same size as the modulus. One can actually use a public exponent of three in RSA, and clearly cubing a number should be faster than raising it to the power of a 2048-bit number.
In 2006, Daniel Bleichenbacher (a fellow Googler) gave a talk at the CRYPTO 2006 rump session where he outlined a bug in several, very common RSA signature verification implementations at the time. The bug wasn't nearly as bad as it could have been because it only affected public keys that used a public exponent of three and most keys used a larger exponent: 216+1. But the fact that a slightly larger public exponent saved these buggy verifiers cemented 216+1 as sensible default value for the public exponent.
But there's absolutely no reason to think that a public exponent larger than 216+1 does any good. I even checked that with Bleichenbacher before writing this. Three should be fine, 216+1 saved some buggy software a couple of times and any larger is probably a mistake.
Because of that, when writing the Go RSA package, I didn't bother supporting public exponents larger than 231-1. But then several people reported that they couldn't verify some DNSSEC signatures. Sure enough, the DNSKEY records for .cz and .us are using a public exponent of 232+1.
DNSSEC is absolutely the last place to use large, public exponents. Busy DNS resolvers have to resolve tens or hundreds of thousands of records a second; fast RSA signature verification is big deal in DNSSEC. So I measured the speed impact of various public exponent sizes with OpenSSL (1.0.1-beta3):
| Public exponent | Verification time (µs) |
|---|---|
| 3 | 10.6 |
| 216+1 | 23.9 |
| 232+1 | 42.7 |
| 2127-1 | 160.7 |
So a public exponent of 232+1 makes signature verification over four times slower than an exponent of three. As DNSSEC grows, and DNSSEC resolvers too, that extra CPU time is going to be a big deal.
It looks like the zones using a value of 232+1 are just passing the -e flag to BIND's dnssec-keygen utility. There's some suggestion that -e used to select 216+1 but silently changed semantics in some release.
So today's lesson is don't pass -e to dnssec-keygen! The default of dnssec-keygen is 216+1 and that's certainly safe. The .com zone uses a value of three and I think that's probably the best choice given the CPU cost and the fact that the original Bleichenbacher bug has been long since fixed.

The development of the language Go is going at a fast pace, hence an updated version of Super-short guide to gettinq q.
Get the latest version (called weekly) of Go:
Get Go: hg clone -u release https://go.googlecode.com/hg/ go
Note the directory you have downloaded it to and set add its bin
directory to your PATH: PATH=$PWD/go/bin.
Update Go to the latest weekly: cd go; hg pull; hg update weekly
Compile Go: cd src, you should now sit in go/src.
And compile: ./all.bash
Install missing commands (gcc, sed, bison, etc.) if needed.
The latest Go is now installed. You should now have the go-tool,
this is the central interface to all Go program building tasks.
$ go
Go is a tool for managing Go source code.
Usage: go command [arguments]
The commands are:
build compile packages and dependencies
clean remove object files
doc run godoc on package sources
fix run go tool fix on packages
....
....
lost more
If you can not run go, check your PATH.
The GOPATH variable specifies (among things) where your Go
code lives. Using the go tool does bring a few requirements
to the table in how to layout the directory structure.
~/g) for your code: mkdir -p ~/g/srcexport GOPATH=~/gcd ~/g/src; git clone git://github.com/miekg/dns.gitcd dns; go buildMakefile here, but it
just calls go multiple times: cd ex; make$GOPATH/bin for the binaries, in this setup that will be ~/g/bin~/g/bin/q mx miek.nl (or add ~/g/bin to your $PATH too)
When we announced forward secrecy for Google HTTPS we noted that “we hope to support IE in the future”. It wasn't that we didn't want to support IE, but IE doesn't implement the combination of ECDHE with RC4. IE (or rather, SChannel) does implement ECDHE with AES on Vista and Windows 7, but I only wanted to make one change at a time.
With the release of MS12-006 a month ago to address the BEAST weakness in TLS 1.0's CBC design, we've now made ECDHE-RSA-AES128-SHA our second preference cipher. That means that Chrome and Firefox will still use ECDHE-RSA-RC4-SHA, but IE on Vista and Windows 7 will get ECDHE now. This change also means that we support ECDHE with Safari (at least on Lion, where I tried it.)
Modern ELF systems can randomize the address at which shared libraries are loaded. This is generally referred to as Address Space Layout Randomization, or ASLR. Shared libraries are always position independent, which means that they can be loaded at any address. Randomizing the load address makes it slightly harder for attackers of a running program to exploit buffer overflows or similar problems, because they have no fixed addresses that they can rely on. ASLR is part of defense in depth: it does not by itself prevent any attacks, but it makes it slightly more difficult for attackers to exploit certain kinds of programming errors in a useful way beyond simply crashing the program.
Although it is straightforward to randomize the load address of a shared library, an ELF executable is normally linked to run at a fixed address that can not be changed. This means that attackers have a set of fixed addresses they can rely on. Permitting the kernel to randomize the address of the executable itself is done by generating a Position Independent Executable, or PIE.
It turns out to be quite simple to create a PIE: a PIE is simply an executable shared library. To make a shared library executable you just need to give it a PT_INTERP segment and appropriate startup code. The startup code can be the same as the usual executable startup code, though of course it must be compiled to be position independent.
When compiling code to go into a shared library, you use the -fpic option. When compiling code to go into a PIE, you use the -fpie option. Since a PIE is just a shared library, these options are almost exactly the same. The only difference is that since -fpie implies that you are building the main executable, there is no need to support symbol interposition for defined symbols. In a shared library, if function f1 calls f2, and f2 is globally visible, the code has to consider the possibility that f2 will be interposed. Thus, the call must go through the PLT. In a PIE, f2 can not be interposed, so the call may be made directly, though of course still in a position independent manner. Similarly, if the processor can do PC-relative loads and stores, all global variables can be accessed directly rather than going through the GOT.
Other than that ability to avoid the PLT and GOT in some cases, a PIE is really just a shared library. The dynamic linker will ask the kernel to map it at a random address and will then relocate it as usual.
This does imply that a PIE must be dynamically linked, in the sense of using the dynamic linker. Since the dynamic linker and the C library are closely intertwined, linking the PIE statically with the C library is unlikely to work in general. It is possible to design a statically linked PIE, in which the program relocates itself at startup time. The dynamic linker itself does this. However, there is no general mechanism for this at present.
"Go is miles ahead of C++ and Java in terms of expressibility and close in terms of performance. It is also relatively simple and has a straightforward interaction with Linux system calls."It's the same experience I made using Go in professional and personal projects. But the next quote shows the importance of the improvement of the garbage collector:
"The main drawback is also its strength - the garbage collector. vtocc has made spot optimizations to minimize most of the adverse effects of Go’s stop-the-world gc. At this point, we are trading some amount of performance for greater creativity and efficiency at lower layers. unless you’re trying to max out on qps for your servers, you should see acceptable performance from vtocc. Also, go’s garbage collector is being improved. So, this should only get better over time. Go’s existing mark-and-sweep garbage collector is sub-optimal for systems that use large amounts of static memory (like caches). In the case of vtocc, this would be the row cache. To alleviate this, we intend to use memcache for the time being. If the gc ends up addressing this, it should be fairly trivial to switch to an in-memory row cache. Note that the row cache functionality is not fully ready yet."Here I'm really looking forward to the next releases.
/home/themue/projectsWhy this 3rd party directory? The new Go tools have a very intelligent way to install external packages in a different directory than own packages. It's based on the environment variable $GOPATH. The naming already shows that it's a path, not only one directory. $GOPATH is the path where commands like go build and go install look for referenced packages they need to compile and link the software. To do so external packages have to be installed before. The command go get will install the sources and the compiled package into the first directory of the path. So the order in the case above should be
/go
/bin
...
/test
/own
/pkg
/src
/3rdparty
/pkg
/src
GOPATH=$HOME/projects/3rdparty:$HOME/projects/ownWhen installing own packages which source is located in .../own/src it will be installed into .../own/pkg.



Just a brief note that I'll be at RSA 2012 in San Francisco at the end of the month and will be speaking with several others about certificate revocation. (tech-106, Tuesday, 1pm.).
If you want to chat and don't manage to grab me then, drop me an email. (agl at imperialviolet.org if you didn't already know.)
Due to the new go tool (long story), I've renamed godns to dns.
This means the github repo is also somewhere else.
godns installed itself as dns so code using it does not need to be changed.

Let my start by apologizing for the noisy duplicate posts. I know that people using RSS software to read this blog got a whole bunch of old posts shown as new yesterday, and the same thing happened again just now. I made some mistakes while moving the blog from one platform to another, which caused the first burp, and then I had to fix the mistakes, which caused the second burp. But it's done, and there won't be another batch of duplicates waiting for you tomorrow.
I've moved this blog off of Blogger onto App Engine, running on a custom app written in Go. The down side is that I had to implement functionality that Blogger used to handle for me, like generating the RSS feed, and that's both extra work and a chance to make mistakes, which I took full advantage of. The up side, however, is that it makes it significantly easier for me to automate the writing and publishing of posts, and to create posts with a computational aspect to the content. I'll be blogging in the coming months about both the new setup, which has some interesting technical aspects behind it (I can edit live posts in a real text editor, for one thing), and about other topics that can make use of the computation.
For now, though, it's just the same content on a new server. Enjoy.
When a browser connects to an HTTPS site it receives signed certificates which allow it to verify that it's really connecting to the domain that it should be connecting to. In those certificates are pointers to services, run by the Certificate Authorities (CAs) that issued the certificate, that allow the browser to get up-to-date information.
All the major desktop browsers will contact those services to inquire whether the certificate has been revoked. There are two protocols/formats involved: OCSP and CRL, although the differences aren't relevant here. I mention them only so that readers can recognise the terms in other discussions.
The problem with these checks, that we call online revocation checks, is that the browser can't be sure that it can reach the CA's servers. There are lots of cases where it's not possible: captive portals are one. A captive portal frequently requires you to sign in on an HTTPS site, but blocks traffic to all other sites, including the CA's OCSP servers.
If browsers were to insist on talking to the CA before accepting a certificate, all these cases would stop working. There's also the concern that the CA may experience downtime and it's bad engineering practice to build in single points of failure.
Therefore online revocation checks which result in a network error are effectively ignored (this is called “soft-fail”). I've previously documented the resulting behaviour of several browsers.
But an attacker who can intercept HTTPS connections can also make online revocation checks appear to fail and so bypass the revocation checks! In cases where the attacker can only intercept a subset of a victim's traffic (i.e. the SSL traffic but not the revocation checks), the attacker is likely to be a backbone provider capable of DNS or BGP poisoning to block the revocation checks too.
If the attacker is close to the server then online revocation checks can be effective, but an attacker close to the server can get certificates issued from many CAs and deploy different certificates as needed. In short, even revocation checks don't stop this from being a real mess.
So soft-fail revocation checks are like a seat-belt that snaps when you crash. Even though it works 99% of the time, it's worthless because it only works when you don't need it.
While the benefits of online revocation checking are hard to find, the costs are clear: online revocation checks are slow and compromise privacy. The median time for a successful OCSP check is ~300ms and the mean is nearly a second. This delays page loading and discourages sites from using HTTPS. They are also a privacy concern because the CA learns the IP address of users and which sites they're visiting.
On this basis, we're currently planning on disabling online revocation checks in a future version of Chrome. (There is a class of higher-security certificate, called an EV certificate, where we haven't made a decision about what to do yet.)
Our current method of revoking certificates in response to major incidents is to push a software update. Microsoft, Opera and Firefox also push software updates for serious incidents rather than rely on online revocation checks. But our software updates require that users restart their browser before they take effect, so we would like a lighter weight method of revoking certificates.
So Chrome will start to reuse its existing update mechanism to maintain a list of revoked certificates, as first proposed to the CA/Browser Forum by Chris Bailey and Kirk Hall of AffirmTrust last April. This list can take effect without having to restart the browser.
An attacker can still block updates, but they have to be able to maintain the block constantly, from the time of revocation, to prevent the update. This is much harder than blocking an online revocation check, where the attacker only has to block the checks during the attack.
Since we're pushing a list of revoked certificates anyway, we would like to invite CAs to contribute their revoked certificates (CRLs) to the list. We have to be mindful of size, but the vast majority of revocations happen for purely administrative reasons and can be excluded. So, if we can get the details of the more important revocations, we can improve user security. Our criteria for including revocations are:
For the curious, there is a tool for fetching and parsing Chrome's list of revoked certificates at https://github.com/agl/crlset-tools.
When people need a list of root certificates, they often turn to Mozilla's. However, Mozilla doesn't produce a nice list of PEM encoded certificates. Rather, they keep them in a form which is convenient for NSS to build from: https://mxr.mozilla.org/mozilla/source/security/nss/lib/ckfw/builtins/certdata.txt?raw=1.
Several people have written quick scripts to try and convert this into PEM format, but they often miss something critical: some certificates are explicitly distrusted. These include the DigiNotar certificates and the misissued COMODO certificates. If you don't parse the trust records from the NSS data file, then you end up trusting these too! There's at least one, major example of this that I know of.
(Even with a correct root file, unless you do hard fail revocation checking you're still vulnerable to the misissued COMODO certificates.)
So, at the prodding of Denton Gentry, I've open-sourced a tool for converting NSS's file to PEM format: extract-nss-root-certs. (At the time of writing it requires a 6g built from the weekly or current tree (hg -r weekly), not the release tree. A few of the APIs have changed since the last Go release was done. This will be resolved when Go 1.0 is released.)
A problem I’ve had for a long while has been the fear of looking stupid. It’s held back projects, study, blog posts (you can see this from the sparseness of this blog), and more generally things I’ve wanted to do which risk looking stupid - translated: worthwhile things.
Ironically this fear has often been self-fulfilling as I’ve ran through the familiar cycle of publicly promising to do something → fearing looking stupid since this thing is tough and I’ve hit up on a brick wall → engaging in endless procrastination → end up looking stupid for not having made progress on said thing.
This is all highly applicable to programming. Computers are so ridiculously complicated that there will always be something to defeat you, the field so wide that there will always be something you don’t know about, or even if you do know something relatively deeply there is always something (actually many things) which will crop up to surprise you (C sharpies should read Eric Lippert’s blog to bring this point home).
A curious aspect of our craft is how quickly you can find yourself in a situation where your particular problem is a unique enough combination of factors for you to be out there on your own at least in some regard or another. That is enough to make the most hardened, experienced developer insecure and is yet another factor in my own battle with the stupid.
Another consequence of this fear is that, since it’s really impossible to improve at something without questioning whether you have the best approach to the problem at hand (and thus risking looking stupid for having got something wrong), you end up less great than you could potentially be.
In terms of programming this fear stands in the way of better code. Without considering whether your code might be suboptimal (and therefore you possibly looking stupid), you end up almost definitely ensuring your code will be suboptimal. This is not unconnected to the only valid measure of code quality.
Clearly a big factor in all of this is pride, especially when you consider future employability, and especially when you have a name which is globally unique over the whole of the internet (the intersection of people with forename of Lorenzo and people with surname of Stoakes, rather than the more common Stokes, is small).
Fuck pride. Fuck not doing things you want to do because you might end up looking stupid, fuck getting stuck on a problem and not bringing the awesome power of crowdsourcing to bear on it.
Expect some stupidity going forward, but also intelligence as I work hard on fixing my stupidity, little-by-little. Sucking a little less each year.
The tool for DNS fingerprinting is fpdns, which is Perl based.
In recent times development seems to have picked up, but a little competition never hurt
anyone, so I wrote fp in Go. Fp is also a fingerprint program for DNS servers. Its aim is to
be more readable then fpdns is (was?). And make it more easy to add new server types.
Do you have some old(er) nameserver laying around that can be queried? Does your (sick) mind
know of a few extra evil queries that can be sent to nameservers? If so, please contact
me: query@evilquery.nl. I want to get to a point where fp sends about 10 queries that
can be used to identify a server.
A fingerprint in fp looks like this:
.,CH,TXT,QUERY,NOERROR,qr,aa,tc,RD,ra,ad,cd,z,1,0,0,0,DO,4097,NSID
It has 20 fields, which are:
. in this example;CH here;TXT here;QUERY;NOERROR;qr, lowercase means false (not set), uppercase means true;aa, lowercase. Thus not set here;tc, not set;RD, uppercase, thus set;ra;ad;cd;z;DO (uppercase, thus set);These fingerprints are also used in creating the DNS queries that are send to nameserver(s) being tested.
A full nameserver fingerprint consists out of multiple of these fingerprints. Right now
fp fires off 3 queries to test a server, so each nameserver fingerprint must also
consist out of 3 fingerprints. The nameserver fingerprint of BIND9
looks like:
# BIND9 fingerprints
.,CH,TXT,QUERY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,NSID
auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,AA,tc,rd,ra,ad,cd,z,1,15,1,0,do,0,nsid
bind.,NONE,SOA,NOTIFY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,0,do,0,nsid
When fp is extended with an extra fingerprint, this BIND9 fingerprint also
needs to get an extra fingerprint.
As said, Currently fp only uses three queries, but this is expected to be increased in the
near future. In the data directory,
the file q holds the fingerprints of the queries to ask. Currently
it looks like this:
# These are the queries that we ask the nameserver being identified
#
# The order is important, as the data files of the known nameservers are compared
# in this order.
.,CH,TXT,QUERY,NOERROR,qr,aa,tc,RD,ra,ad,cd,z,1,0,0,0,DO,4097,NSID
auThoRs.bInD.,CH,TXT,QUERY,NOERROR,qr,aa,tc,rd,ra,ad,cd,z,1,0,0,0,do,0,nsid
bind.,NONE,SOA,NOTIFY,NOERROR,qr,AA,tc,RD,ra,ad,cd,Z,1,0,0,0,do,0,nsid
A local run looks like this (this is abbreviated):
% ./fp @localhost
Server type Diffs Fingerprint Recevied
Bind9 0 .,CH,TXT,QUERY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,NSID .,CH,TXT,QUERY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,NSID
Bind9 0 auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,AA,tc,rd,ra,ad,cd,z,1,15,1,0,do,0,nsid auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,AA,tc,rd,ra,ad,cd,z,1,15,1,0,do,0,nsid
Bind9 0 bind.,NONE,SOA,NOTIFY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,0,do,0,nsid bind.,NONE,SOA,NOTIFY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,0,do,0,nsid
=
Differences: 0
Nsd3 2 .,CH,TXT,QUERY,NOERROR,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,nsid .,CH,TXT,QUERY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,NSID
Nsd3 3 auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,aa,tc,rd,ra,ad,cd,z,1,0,0,0,do,0,nsid auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,AA,tc,rd,ra,ad,cd,z,1,15,1,0,do,0,nsid
Nsd3 6 .,CLASS0,TYPE0,NOTIFY,NXDOMAIN,QR,AA,tc,RD,ra,ad,cd,z,0,0,0,0,do,0,nsid bind.,NONE,SOA,NOTIFY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,0,do,0,nsid
=
Differences: 11
What do you see here? On the left the nameserver type we're testing, then a number. This number represent the number of differences with the
stored fingerprint for this server. When this number is zero, it means the reply from the unknown server is an exact match with
one of the stored fingerprints. In general, the lower the number, the more exact the hit was.
For bind9 in the example above, the accumulated number of differences is zero. This indicates the server is probably a BIND9 server.
For nsd3 the story is completely different. The accumulated number of differences is 11, so this server probably isn't a NSD3 server.
With, -report fp will just show the fingerprint of a nameserver. If the server is positively identified, the finger
print can be added to fp:
% ./fp -report @localhost
# Fingerprint of <Nameserver> <version>
# Supplied by <Name> on <Date>
#
.,CH,TXT,QUERY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,1,DO,4096,NSID
auThoRs.bInD.,CH,TXT,QUERY,NOERROR,QR,AA,tc,rd,ra,ad,cd,z,1,15,1,0,do,0,nsid
bind.,NONE,SOA,NOTIFY,REFUSED,QR,aa,tc,RD,ra,ad,cd,z,1,0,0,0,do,0,nsid
For those who didn’t know, I have quit my job at a hedge fund to work at a startup - Rulemotion (website under construction). Exciting! Scary! Awesome! All at the same time :-)
I don’t move until early March, at which I point I am sure I shall blog some more about what I’m getting up to there/what we are all about.
Already looking to be an interesting year, this!
Get the latest version (called weekly) of Go:
Get Go: hg clone -u release https://go.googlecode.com/hg/ go
Note the directory you have downloaded it to and set
$GOROOT to it: export GOROOT=$PWD/go.
Add the GOROOT bin directory to your path: PATH=$PATH:$GOROOT/bin
Update Go to the latest weekly: cd $GOROOT; hg pull; hg update weekly
Compile Go: cd $GOROOT/src ; ./all.bash
Install missing commands (gcc, sed, bison, etc.) if needed.
The latest Go is now installed.
cd ~; git clone git://github.com/miekg/godns.gitcd godns; make ; make installcd examples; make ; make installq mx miek.nl

In January 2007 I posted an article on my web site titled “Regular Expression Matching Can Be Simple And Fast.” I intended this to be the first of three; the second would explain how to do submatching using automata, and the third would explain how to make a really fast DFA. These were inspired by my work on Google Code Search.
Today, the fourth article in my three-part series is available, accompanied by source code (as usual). This one describes how Code Search worked.

(See the original post for background.)
Everyone seems to have settled on 1/n-1 record splitting as a workaround for the BEAST attack in TLS 1.0 and SSLv3. Briefly: 1/n-1 record splitting breaks CBC encrypted records in two: the first with only a single byte of application data and the second with the rest. This effectively randomises the IV and stops the attack.
The workaround which OpenSSL tried many years ago, and which hit significant issues, was 0/n record splitting. It's the same thing, but with the first record being empty. The problem with it was that many stacks processed the empty record and returned a 0-byte read, which higher levels took to mean EOF.
1/n-1 record splitting doesn't hit that problem, but it turns out that there's a fair amount of code out there that assumes that the entire HTTP request comes in a single read. The single byte record breaks that.
We first implemented 1/n-1 record splitting in Chrome 15 but backed off after only a couple of days because logging into several large sites broke. But that did motivate the sites to fix things so that we could switch it on in Chrome 16 and it stuck that time.
Opera also implemented it around this time, but I think Chrome took the brunt of the bug reports and it's time consuming dealing with them. Myself and a colleague have been emailing and phoning a lot of sites and vendors while dealing with upset users and site admins. Chrome certainly paid a price for moving before Firefox and IE but then we're nice like that.
Thankfully, this week, Microsoft released a security update which implements 1/n-1 record splitting in SChannel and switches it on in IE. (Although it defaults to off for other users of SChannel, unlike NSS.) Now the sites which broke with Chrome 16 are also broken in a patched IE and that takes some pressure off us. In a few weeks, Firefox 10 should be released and then we'll be about as good as we're going to get.
After taking the brunt with Chrome 16, there is one case that I'm not going to fight: Plesk can't handle POST payloads that don't come in a single read. Chrome (currently) sends POSTs as two writes: one for the HTTP headers and a second for the POST body. That means that each write is split into two records and Plesk breaks because of the second split. IE and Firefox send the headers and body in a single write, so there's only a single split in the HTTP headers, which Plesk handles.
Chrome will start merging small POST bodies into the headers with Chrome 17 (hopefully) and this will fix Plesk. Also, merging as Firefox and IE do saves an extra packet so it's worthwhile on its own. Once again, anything that's mostly true soon becomes an unwritten rule on the Internet.
It's worth contrasting the BEAST response to the renegotiation attack. The BEAST workaround caused a number of problems, but it worked fine for the vast majority of sites. The renegotiation fix requires that very nearly every HTTPS site on the Internet be updated and then that browsers refuse to talk to unpatched servers.
I'd bet that we'll not manage to get enough patched servers for any browser to require it this side of 2020. Unpatched servers can still disable renegotiation to protect themselves, but it's still not hard to find major sites that allow insecure renegotiation (www.chase.com was literally the second site that I tried).
“Off the record” is, unfortunately, an overloaded term. To many it's feature in gTalk and AOL IM which indicates that the conversation isn't logged. However, to crypto folks it's a protocol for secure chat.
(In fact, resoloving the ambiguity is on the EFF's wish list.)
Pidgin has been my chat client of choice for some time because it's pretty fully featured and supports OTR via a plugin. However, I just don't trust it from a security point of view. The latest incident was only a couple of weeks ago: CVE-2011-3919.
So, I implemented otr in Go, as well as an XMPP library and client. It's an absolutely minimal client (except for OTR support) and implements only what I absolutely need in a client.
But it does mean that the whole stack, including the TLS library, is implemented in a memory safe language. (On the other hand, pretty much everything in that stack, from the modexp function to the terminal handling code was written by me and has never really been audited. I'm a decent programmer but I'm sure there are some howlers of security issues in there somewhere.)

I've been writing a graphics library in Go for the mental exercise of the task. I'll be posting examples in here.  |

“Nothing is so strong as gentleness, nothing so gentle as real strength”
- St. Francis de Sales

Go Gopher
As 2011 makes its way out and 2012 takes its place, it’s time for a bit of reflection and a bit of looking forward. I haven’t been writing software professionally for particularly long, but I have written software in a number of languages (everything from Pascal to Python), and I think we can all agree that none of the usual suspects are particularly ideal. If you’re like me, you hunker down with your favorite set of language features and write your code in as much isolation as possible, so that you can work around or ignore whatever problems your language and/or environment cause you. You probably have some tools lying around to help you do various things for which the language or your editor/environment aren’t well-equipped. You probably don’t even realize all of the things that bother you about the language after awhile, because it’s the norm: every programmer has to deal with them, it just comes with the territory. Please note: I will be comparing Go to other languages extensively in this blog post; do not take it to be an indictment of them or even, really, as reasons to not use them. I’m simply giving my opinion on their differences and why I personally find that Go is a more suitable language for my development. I have used all of the languages that I discuss and will continue to use them when their particular strengths are required.
Let’s start with Python. I loved my time writing Python, because I felt like I could be really productive. I created a library that my team and I could use to replace huge pieces of boilerplate with a few lines of very terse but legible code. I used just about every new, shiny feature of Python on which I could get my grubby little hands: I used context objects, generators, fancy inheritance and especially I abused the data model in ways that now make me cringe. My code was a pleasure to read and even more of a pleasure to write. It got the job done with a really small amount of code, and my team and managers loved me for how productive I was and how productive I was making my team. What I knew somewhere in the back of my mind but didn’t tell anyone was how horribly painful it was to debug the code written this way. My code reviewers were able to read the code and admit that it looked right, see that the test cases were comprehensive enough and verify that I was covering all of the requirements, but I doubt that they had any idea what was really going on behind-the-scenes or how brittle some of the libraries could be. Since I had written one of the libraries myself and knew most of the nuances of the Python features employed, I was able to debug problems with the library (or my use of it) with relative ease. Unfortunately, it often meant tracing through many layers and scrutinizing pieces of code with a fine-toothed comb to find all of the places where Python was secretly calling (or not calling) out to other pieces of code. Often, it was simply a matter of hiding yet another __special__ function to an object to handle a new use case (for those of you familiar with C++ and the Rule of 3, there needs to be a Python Rule of 17 or something…) that wasn’t already covered. The rest of the team pretty much just used my example code as a template and never ran into these issues, but if they’re still using this particular library I really hope that it’s not causing them more problems than it solved. I’m not even going to get into the various issues that flimsy duck-typing and non-static typing can cause, often a long time after the offending code is written… What remains clear to me is that Python (and langauges like it) are not suitable for large-scale development without very strict adherence to a style guide which precludes almost all of what I described above, and to me that would just take all of the fun out of it.
That, however, is Python, and is the price you expect to pay for such a dynamic language. Even lower-level languages like C and Pascal have their issues. Don’t get me wrong, I absolutely love C and feel like I am a deus intra machinam whenever I write it; I still think it’s the first programming language that a student should learn, and that they shouldn’t be able to move to a higher- or lower-level language until they’ve mastered it. The problem with these languages, especially C, is that you have to take such care when writing and reviewing any significant amount of code that verifying that the code is correct, robust, and has no memory leaks is the next closest thing to impossible. The boilerplate and the bookkeeping that have to be done before you even get to the meat of your application or algorithm are tedious and error-prone in the worst way. There are certainly situations in which such lower-level languages are the only language that can solve your problem, whether it be for performance, real-time/deterministic execution or bare metal proximity reasons, but they just aren’t the most suitable languages for large-scale development.
I’ve also done a bit of graphical (read: drag-and-drop, flow chart) programming, which is interesting to say the least. I won’t go into much detail here, except to say that from my limited exposure, it seems best suited as a special-purpose tool for small- to medium-scale logic at best, and should probably not be used when there are more than a few developers on a particular piece of “code.” It’s fun at first, but the limitations show up fast, and after awhile it seems more tedious, repetitive, and limiting than anything else.

Go even has an adorable mascot
Enter Go. It is a new programming language by pretty much any definition, despite having been in development at Google since 2007 and as an open source project since 2009. It’s a compiled, statically typed, garbage collected language with some cool primitives for concurrency. Despite being compiled and statically typed, it has a very dynamic feel. The syntax has some concise shortcuts to minimize repetition and variable typing. The presence of closures, a garbage collector, and a fairly expansive standard library also contribute to its dynamic feel. These things, coupled with the clarity and explicit nature of Go source code, all help make Go one of the best general purpose languages that I have ever used. I won’t be providing code directly (this blog post is long enough already), but many of the links I provide will be to the documentation or to the relevant portions of the Go Tour, where you can play with the features yourself.
We look forward to the first long-term stable release of the Go standard library and compilers sometime early this year: Go version 1. I’ve been convinced for awhile now that Go is a production-ready language, but in my mind this piece is really the last thing left barring wider adoption. There are some exciting language changes leading up to this Go 1 release, and I am really excited to see what gets done after it is finished. To date, the fast pace at which Go has evolved (both the language and the standard libraries) has posed a challenge for third-party library maintainers, who often have to maintain both a “release” branch of their code and a “weekly” branch due to the rate at which the weekly branch progresses and the relatively high percentage of Go users who are doing their development at (or beyond) the “weekly” branch to take advantage of the new, shiny features or to get the latest bug fixes. With Go 1 this should change, and the number of libraries available to use with a single command (more on that later) will be able to grow even faster.
Compared to most languages in use today, Go was designed with many programmers, concurrent systems, and large-scale problems in mind. Some languages, like C, were simply not designed at a time where multicore and multiprocessor systems were in broad deployment. Some languages, like Python, weren’t originally intended to scale well onto multiple cores and have been slow to adopt strategies for utilizing such resources. Many languages to this day don’t have networking libraries which work predictably and have a clean, understandable API. Programs written in many languages, especially those with operator overloading, require in-depth knowledge of both the architecture of the program itself and the libraries in use in order to be able to understand the code well. Go attempts to address all of these problems and more; in my opinion, it does so brilliantly.
Two of the first things you will hear most people talk about when you hear about Go are channels and goroutines. They’re certainly two of the “shiniest” features of the language, and are the reasons why I tried out Go back in late 2009. They’re far from the biggest reasons why I think you should try Go, but they’re as good a place as any to start.
These two features are inspired by Hoare’s Communicating Sequential Processes (CSP). A goroutine (similar to a coroutine) is a function that runs independently of the calling function. They’re similar to threads in that a scheduler manages which ones are running at any given time, but they are much lighter-weight than their operating system counterparts. In fact, a Go application with many thousands of goroutines can run comfortably on a single operating system thread.
Channels are a data type in Go which allows for simple, clear communication between goroutines. They are first-class values that have a data type associated with them. Any value of the associated type can be sent over the channel and then received from the channel, usually by another goroutine. They can be passed into functions and goroutines, stored in objects, even sent through other channels.
In most programming languages, when you have multiple threads that need to share data or communicate, you arrange to do so via the use of mutual exclusion locks (mutexes). At first glance, it seems simple: before you access the data you lock it, and when you’re done you unlock it. It gets more complicated very quickly, of course. In Go, a mutex (while available) is not the preferred solution to most problems. As stated in Effective Go, the slogan has become:
Do not communicate by sharing memory; instead, share memory by communicating.Thus instead of using a mutex to protect a shared, global object, you either pass the object around (changing ownership as you do) or you maintain a single owner and all other goroutines access the object by sending requests to that goroutine.
Using these two tools, it turns out to be quite easy to implement solutions to a problem that make logical sense and that very closely reflect the way we might solve the problem in our head. Small, focused pieces of code are concerned with specific aspects of the solution, and are either given their input via the usual way (function parameters) or continually from channels (they also have the same alternatives available for their output). Ownership of data is clear, communication is explicit, the code is highly legible. Such designs are also often easy to unit test; simulating the input and verifying the output via channels is straightforward and very common.
One of the many features of Go that makes it have a very dynamic feel are closures. Like lambdas in python or blocks in ruby, a function can be declared as a local variable or even passed as a literal to a function. All local variables in scope at the closure declaration are also in scope within the closure. They’re powerful tools for functional-style APIs and can be a really fun alternative to (or improvement upon) callbacks. They are also commonly executed directly as a goroutine.
In addition to the “go” directive that runs a function in its own goroutine, Go also has a “defer” directive. When a function (or closure) call is preceded by the “defer,”, the call is evaluated but not executed until just before the function returns. Multiple deferred calls will be executed in reverse order. This turns out to be a very powerful tool for using any object or API which requires cleanup: as soon as you create it or lock it, you can defer the cleanup or unlock. This makes it very easy to spot when you forgot to close a file descriptor or (should you find yourself using one) unlocking a mutex.
These two features provide the ability to confine relevant code all in the same place, which in turn makes reading, debugging, and maintaining the code easier. This is a common theme, and I think was at or near the top of the Go designers’ priority list when designing the language. The concepts are simple, orthogonal, and flexible without sacrificing readability, debuggability, or maintainability.
Interfaces in Go are a welcome twist on a familiar concept. Typically, in a language like Java, interfaces must be explicitly declared by any implementing class. This, of course, means that adding a new interface requires modifying (and having access to modify) all classes that you plan to use in values of that interface type. The paradigm in Go is reversed: instead of defining an interface and declaring all of the objects that satisfy it, the interface is defined and any object which could satisfy the interface can implicitly be used as a value of the interface. This also provides a useful tool, the empty interface, which acts as a container for any possible value (similar to Java’s Object, from which all classes are derived) because all values satisfy it.
In contrast to interfaces in other languages (for instance, in Java), Go interfaces are often very small, and contain one or just a few methods. Because of the presence of such small interfaces in the standard library, they have naturally given rise to some common, idiomatic function names and signatures. Possibly the best examples of these from the standard library are the io.Reader and io.Writer interfaces. Because of the prevalence of objects which implement these two interfaces, stringing together producers and consumers of a data stream is often reminiscent of a unix pipeline. It is simple, for instance, to open a file, unzip it, decrypt its contents, and stream it directly to an HTTP client because all of these interfaces satisfy or consume the above interfaces. Even Go’s version of the old favorite printf can write to any object which satisfies the io.Writer interface, which gives rise to the very concise web-based version of “Hello, World!” in Go.
Some of the best features of Go are, unlike those listed above, not something you’ll find listed in the specification. They probably stem from the guiding philosophy behind its design more than anything else. I think that the simplicity, orthogonality, and explicitness of the features of the Go language make it a prime candidate for a teaching language, especially at the middle- or high-school level.
First, the features of Go are simple and minimal. The entire language specification fits in 45 printed pages. By contrast, the C++ specification clocks in at 750 pages and Javascript has nearly 250. It is short enough that an average programmer can actually read it, understand it, and internalize it in its entirety. This turns out to be quite an asset in a large project setting with multiple developers, each of whom will have a slightly different coding style and may utilize a different different set of features. Being able to understand all of the language features in use, their nuances, and their side effects turns out to be easy in Go when it could be a nearly impossible task in many others.
Second, the features of Go are designed to be orthogonal to one another. When you understand two concepts independently, you understand them together. I have already given one example of this: deferred function calls. If you understand defer (e.g. that it doesn’t make the call immediately, that it evaluates arguments at the defer site, and that it is executed after any subsequent defer calls as the function returns) and you understand closures (that any local variables are in scope, etc), you already understand what happens if you defer a call to a function literal. Compare this to my Python anecdotes earlier, and you’ll find that this is not as ubiquitous a quality as you might expect. There are also a fair number of C++ and Java features that interact non-orthogonally and require some more in-depth understanding (hence the 750-page C++ specification).
This one is more difficult to quantify. I have found, qualitatively, that writing Go is easier and more fun than pretty much any other language I have used to date. Dynamic languages like Python and Ruby are fun to learn and are fun languages with which to experiment, but I have found that the amount of time spent debugging them (especially when it’s somebody else’s code) takes almost all of the fun out of large project and multi-developer situations. By contrast, languages like C and C++ (and to a somewhat lesser extent, Java) are more painful to write up front but have well-established tools that make analyzing and debugging them a much more pleasant experience. Until I tried Go, I accepted this as the nature of the beast. You just had to to choose. With Go, however, I think the designers managed to strike a balance.
On the development side, I have found that it is easy to translate designs into code. As I mentioned previously, channels and goroutines make it easy to implement your design in pieces that all connect together and communicate. The lack of verbose syntaxes for declarations and the implicit nature of interfaces reduce the amount of arguably unnecessary up-front work. The simplicity of the type system lets you (or forces you to) focus on the implementation instead of fixating on design patterns or type hierarchies. The lack of certain features in the language like operator overloading, destructors, exceptions, and the like all force code to be explicit. An oft-quoted mailing list post by Andrew Gerrand states that “[in] Go, the code does exactly what it says on the page.” Error handling, function calls, math, map/slice access and inter-goroutine communication all look exactly like what they are. When examining a function in isolation, it is a relatively small feat to understand the side-effects of a given statement, which makes the debugging process much more pleasant than in some other languages in which the simplest statement like “a+b” could potentially have unlimited side effects.
Outside of the code itself, there are many benefits to the Go programming language. The standard library is very complete, cohesive, and easy to understand. The third party package ecosystem is nurtured by the Go team, and the standard distribution includes an application called “goinstall” (soon to be bundled into a “go” meta-command) by means of which a package hosted in any web-accessible Git, Mercurial, or Subversion repository can be installed (and any such dependencies, ad infinitum) with a single command. By default, such installations are anonymized and aggregated on a package dashboard, which shows the most- and most-recently installed packages as well as their build status as of the latest release. The standard distribution also includes a formatting tool called “gofmt” which knows how to format a piece of source code according to “Go style,” which reduces or eliminates the need for unproductive debating within a project about things like brace placement or whitespace around operators. There is also a tool called “gofix” which contains modules to automatically fix up any mechanical changes that have been made to the standard library or language between releases (for instance, changing function names, package imports or method signatures) where possible. The last of the tools that I will mention is “godoc,” which is similar to pydoc or javadoc. It uses the comments in the source to provide easily accessible documentation both on the command-line and from a web browser. All of these tools add up to make even the experience of development that doesn’t involve code production as easy as possible.
Go is an industrial-strength programming language for solving industrial-sized problems. There are many features that I haven’t even touched upon, like the fact that Go is now the third runtime on Google App Engine, which could probably fill another equally long blog post. If you read this far, I hope you at least take the time to take the Go tour or peruse the language specification. Keep an eye out for future projects or tools where you might be able to try out a new language. You may not like it, it may not be accepted in your place of work, or it may simply not be adequate for your needs, but I think that it has the potential to make significant waves in the software industry and I encourage everyone (even if you’ve never programmed before in your life) to give it a shot.
It’s been a long time since I’ve updated this blog, and a completely crazy past few months, so I hope to rectify the former by using the latter as the basis for this post :)
I turned 30 this September, and the force of switching from the deferring-friendly 20’s (‘I can achieve these things, don’t worry, I’m still young’) to the ‘oh shit I’m an adult now’ 30’s has hit harder than I expected (in fact, to be honest, I didn’t expect it at all).
So what’s happened? Well in my personal life, I finally did something about my weight issue and lost ~3.5 stone (~50lb, ~23kg).
In my intellectual/geek life I committed to the open Stanford AI course and completed it with a 98.7% average*, and wrote notes for the purposes of actual applying the course to real things (the notes are not yet fully complete, however I do plan to finish that later), which has really helped with my recently very low intellectual confidence.
Two fundamental things have changed - firstly I’ve got organised about things (for weight loss - food diary, for study - committed, realistic work schedule), secondly and far more importantly, I’ve stopped beating myself up quite as badly about everything. Beating yourself up like that makes you incapable of doing anything since you feel constantly bad about whatever it is you’re doing, and thus reticent to do it, which means you don’t improve/change anything, which means you beat yourself up more, etc. - a vicious, vicious cycle.
Another thing to note here is the amazing usefulness of timeboxing. The past week I have got more hacking done in a week than I have for hundreds of weeks prior.
So what about resolutions? Over the coming year I plan to contribute considerably more to go, and build weak into a fully-fledged chess engine (though I can make no guarantees to its eventual strength) and I intend to work on improving my algorithmic and computer science fundamentals knowledge. On the final bit - I plan to enter the google code jam and blog about the experience, though I don’t expect or predict any sort of performance, it’s more of a motivation and point of focus.
Happy New Year!
* I’m not boasting here. I fell considerably below the performance of many other participants and wish I’d been more careful with many of the answers. Also I realised how rusty I am at this stuff. Also I couldn’t stand to carry on attending the meetup I was attending given how erudite, intelligent and informed the other people were compared to me.
As both of my faithful readers can see, my blog postings have dropped significantly. I’ve been posting my random little comments on Google+ instead.
Which leads me to the following. There is a hard-core group of people who only use free software. I’m not quite that hard-core, but in practice I do use only free software, except perhaps for some binary drivers in the kernel (I don’t actually know whether the systems I’m running use binary drivers or not, and I’m not hard-core enough to find out).
I’ve seen some people argue that if you are serious about using free software, you should also only use Internet services which are themselves free software. For example, you should not use Facebook or Google+, because the software used to run those services is not free.
I don’t agree with that argument. The key goal of free software is that I always have the right to change the software that I am running. When I use an Internet service like Google+, I am not running the software. Even if I had a copy of the software, I would not be able to run it, because I don’t have enough servers. And even if I had enough servers, it would be useless for me to run the software, because I don’t have the data. And there is no way to grant me access to the data, because that would violate the reasonable privacy choices of everybody else using the service.
When it comes to a service like Google+, whether the software is free is not important. Releasing the software would not give me any more freedom than I already have. Google+ is only interesting when many people are operating out of a single shared data base, and that data base must have privacy safeguards to ensure that it is not copied.
What matters with Google+ is not the software, but the data. It is important that I be able to retrieve all my data associated with Google+, and that I be able to retrieve it in a way that makes it possible to use with other software. That is, I should be able to retrieve my posts, my comments on other people’s posts, my list of followers, my photos, etc. And I should be able to plug them into some other software service if I so choose.
In fact Google+ does have a set of APIs which permit me to retrieve my data. I haven’t verified that all Google+ data is available via the APIs, but all the obvious stuff seems to be available. Given those APIs, it should be possible for me to move all my data to some other service which provides te required APIs itself.
So I personally don’t see any reason why even a hard-core free software supporter should avoid using a service like Google+. This isn’t to say that it wouldn’t be nice if Google freed up the software and accepted patches from outside users. It’s just that that is not a critical part of freedom to use software.

My name is Patrick Crosby and I'm the founder of a company called Numerotron. We recently released StatHat. This post is about why we chose to develop StatHat in Go, including details about how we are using Go.
StatHat is a tool to track statistics and events in your code. Everyone from HTML designers to backend engineers can use StatHat easily, as it supports sending stats from HTML, JavaScript, Go, and twelve other languages.
You send your numbers to StatHat; it generates beautiful, fully-embeddable graphs of your data. StatHat will alert you when specified triggers occur, send you daily email reports, and much more. So instead of spending time writing tracking or reporting tools for your application, you can concentrate on the code. While you do the real work, StatHat remains intensely vigilant, like an eagle in its mountaintop nest, or a babysitter on meth.
Here's an example of a StatHat graph of the temperature in NYC, Chicago, and San Francisco:

Architecture Overview
StatHat consists of two main services: incoming statistic/event API calls and the web application for viewing and analyzing stats. We wanted to keep these as separate as possible to isolate the data collection from the data interaction. We did this for many reasons, but one major reason is that we anticipate handling a ton of automated incoming API HTTP requests and would thus have different optimization strategies for the API service than a web application interacting with humans.

The web application service is multi-tiered. The web server processes all requests and sends them to an interactor layer. For simple tasks, the interactor will handle generating any necessary data. For complex tasks, the interactor relies on multiple application servers to handle tasks like generating graphs or analyzing data sets. After the interactor is finished, the web server sends the result to a presenter. The presenter responds to the HTTP request with either HTML or JSON. We can horizontally scale the web, API, application servers, and databases as the demand for services grows and changes over time. There is no single point of failure as each application server has multiple copies running. The interactor layer allows us to have different interfaces to the system: http, command line, automated tests, mobile API. StatHat uses MySQL for data storage.
Choosing Go
When we designed StatHat, we had the following check list for our development tools:
We evaluated many popular and not-so-popular web technologies and ended up choosing to develop it in Go.
When Go was released in November 2009, I immediately installed it and loved the fast compilation times, goroutines, channels, garbage collection, and all the packages that were available. I was especially pleased with how few lines of code my applications were using. I soon experimented with making a web app called Langalot that concurrently searched through five foreign language dictionaries as you typed in a query. It was blazingly fast. I put it online and it's been running since February, 2010.
The following sections detail how Go meets StatHat's requirements and our experience using Go to solve our problems.
Runtime
We use the standard Go http package for our API and web app servers. All requests first go through Nginx and any non-file requests are proxied to the Go-powered http servers. The backend servers are all written in Go and use the rpc package to communicate with the frontend.
Templating
We built a template system using the standard template package. Our system adds layouts, some common formatting functions, and the ability to recompile templates on-the-fly during development. We are very pleased with the performance and functionality of the Go templates.
Tinkering
In a previous job, I worked on a video game called Throne of Darkness that was written in C++. We had a few header files that, when modified, required a full rebuild of the entire system, 20-30 minutes long. If anyone ever changed `Character.h`, he would be subject to the wrath of every other programmer. Besides this suffering, it also slowed down development time significantly.
Since then, I've always tried to choose technologies that allowed fast, frequent tinkering. With Go, compilation time is a non-issue. We can recompile the entire system in seconds, not minutes. The development web server starts instantly, tests complete in a few seconds. As mentioned previously, templates are recompiled as they change. The result is that the StatHat system is very easy to work with, and the compiler is not a bottleneck.
RPC
Since StatHat is a multi-tiered system, we wanted an RPC layer so that all communication was standard. With Go, we are using the rpc package and the gob package for encoding Go objects. In Go, the RPC server just takes any Go object and registers its exported methods. There is no need for an intermediary interface description language. We've found it very easy to use and many of our core application servers are under 300 lines of code.
Libraries
We don't want to spend time rewriting libraries for things like SSL, database drivers, JSON/XML parsers. Although Go is a young language, it has a lot of system packages and a growing number of user-contributed packages. With only a few exceptions, we have found Go packages for everything we have needed.
Open source
In our experience, it has been invaluable to work with open source tools. If something is going awry, it is immensely helpful to be able to examine the source through every layer and not have any black boxes. Having the code for the language, web server, packages, and tools allows us to understand how every piece of the system works. Everything in Go is open source. In the Go codebase, we frequently read the tests as they often give great examples of how to use packages and language features.
Performance
People rely on StatHat for up to the minute analysis of their data and we need the system to be as responsive as possible. In our tests, Go's performance blew away most of the competition. We tested it against Rails, Sinatra, OpenResty, and Node. StatHat has always monitored itself by tracking all kinds of performance metrics about requests, the duration of certain tasks, the amount of memory in use. Because of this, we were able to easily evaluate different technologies. We've also taken advantage of the benchmark performance testing features of the Go testing package.
Application-Level Concurrency
In a former life, I was the CTO at OkCupid. My experience there using OKWS taught me the importance of async programming, especially when it comes to dynamic web applications. There is no reason you should ever do something like this synchronously: load a user from the database, then find their stats, then find their alerts. These should all be done concurrently, yet surprisingly, many popular frameworks have no async support. Go supports this at the language level without any callback spaghetti. StatHat uses goroutines extensively to run multiple functions concurrently and channels for sharing data between goroutines.
Hosting and Deployment
StatHat runs on Amazon's EC2 servers. Our servers are divided into several types:
There are at least two of each type of server, and they are in different zones for high availability. Adding a new server to the mix takes just a couple of minutes.
To deploy, we first build the entire system into a time-stamped directory. Our packaging script builds the Go applications, compresses the CSS and JS files, and copies all the scripts and configuration files. This directory is then distributed to all the servers, so they all have an identical distribution. A script on each server queries its EC2 tags and determines what it is responsible for running and starts/stops/restarts any services. We frequently only deploy to a subset of the servers.
More
For more information on StatHat, please visit stathat.com. We are releasing some of the Go code we've written. Go to www.stathat.com/srcfor all of the open source StatHat projects.
To learn more about Go, visit golang.org.

This article was written by Reinaldo Aguiar, a software engineer from the Search team at Google. He shares his experience developing his first Go program and launching it to an audience of millions - all in one day!
I was recently given the opportunity to collaborate on a small but highly visible "20% project": the Thanksgiving 2011 Google Doodle. The doodle features a turkey produced by randomly combining different styles of head, wings, feathers and legs. The user can customize it by clicking on the different parts of the turkey. This interactivity is implemented in the browser by a combination of JavaScript, CSS and of course HTML, creating turkeys on the fly.

Once the user has created a personalized turkey it can be shared with friends and family by posting to Google+. Clicking a "Share" button (not pictured here) creates in the user's Google+ stream a post containing a snapshot of the turkey. The snapshot is a single image that matches the turkey the user created.
With 13 alternatives for each of 8 parts of the turkey (heads, pairs of legs, distinct feathers, etc.) there are more than than 800 million possible snapshot images that could be generated. To pre-compute them all is clearly infeasible. Instead, we must generate the snapshots on the fly. Combining that problem with a need for immediate scalability and high availability, the choice of platform is obvious: Google App Engine!
The next thing we needed to decide was which App Engine runtime to use. Image manipulation tasks are CPU-bound, so performance is the deciding factor in this case.
To make an informed decision we ran a test. We quickly prepared a couple of equivalent demo apps for the new Python 2.7 runtime (which provides PIL, a C-based imaging library) and the Go runtime. Each app generates an image composed of several small images, encodes the image as a JPEG, and sends the JPEG data as the HTTP response. The Python 2.7 app served requests with a median latency of 65 milliseconds, while the Go app ran with a median latency of just 32 milliseconds.
This problem therefore seemed the perfect opportunity to try the experimental Go runtime.
I had no previous experience with Go and the timeline was tight: two days to be production ready. This was intimidating, but I saw it as an opportunity to test Go from a different, often overlooked angle: development velocity. How fast can a person with no Go experience pick it up and build something that performs and scales?
Design
The approach was to encode the state of the turkey in the URL, drawing and encoding the snapshot on the fly.
The base for every doodle is the background:

A valid request URL might look like this: http://google-turkey.appspot.com/thumb/20332620
The alphanumeric string that follows "/thumb/" indicates (in hexadecimal) which choice to draw for each layout element, as illustrated by this image:

The program's request handler parses the URL to determine which element is selected for each component, draws the appropriate images on top of the background image, and serves the result as a JPEG.
If an error occurs, a default image is served. There's no point serving an error page because the user will never see it - the browser is almost certainly loading this URL into an image tag.
Implementation
In the package scope we declare some data structures to describe the elements of the turkey, the location of the corresponding images, and where they should be drawn on the background image.
var (
// dirs maps each layout element to its location on disk.
dirs = map[string]string{
"h": "img/heads",
"b": "img/eyes_beak",
"i": "img/index_feathers",
"m": "img/middle_feathers",
"r": "img/ring_feathers",
"p": "img/pinky_feathers",
"f": "img/feet",
"w": "img/wing",
}
// urlMap maps each URL character position to
// its corresponding layout element.
urlMap = [...]string{"b", "h", "i", "m", "r", "p", "f", "w"}
// layoutMap maps each layout element to its position
// on the background image.
layoutMap = map[string]image.Rectangle{
"h": {image.Pt(109, 50), image.Pt(166, 152)},
"i": {image.Pt(136, 21), image.Pt(180, 131)},
"m": {image.Pt(159, 7), image.Pt(201, 126)},
"r": {image.Pt(188, 20), image.Pt(230, 125)},
"p": {image.Pt(216, 48), image.Pt(258, 134)},
"f": {image.Pt(155, 176), image.Pt(243, 213)},
"w": {image.Pt(169, 118), image.Pt(250, 197)},
"b": {image.Pt(105, 104), image.Pt(145, 148)},
}
)
The geometry of the points above was calculated by measuring the actual location and size of each layout element within the image.
Loading the images from disk on each request would be wasteful repetition, so we load all 106 images (13 * 8 elements + 1 background + 1 default) into global variables upon receipt of the first request.
var (
// elements maps each layout element to its images.
elements = make(map[string][]*image.RGBA)
// backgroundImage contains the background image data.
backgroundImage *image.RGBA
// defaultImage is the image that is served if an error occurs.
defaultImage *image.RGBA
// loadOnce is used to call the load function only on the first request.
loadOnce sync.Once
)
// load reads the various PNG images from disk and stores them in their
// corresponding global variables.
func load() {
defaultImage = loadPNG(defaultImageFile)
backgroundImage = loadPNG(backgroundImageFile)
for dirKey, dir := range dirs {
paths, err := filepath.Glob(dir + "/*.png")
if err != nil {
panic(err)
}
for _, p := range paths {
elements[dirKey] = append(elements[dirKey], loadPNG(p))
}
}
}
Requests are handled in a straightforward sequence:
Should any error occur, we serve the defaultImage to the user and log the error to the App Engine dashboard for later analysis.
Here's the code for the request handler with explanatory comments:
func handler(w http.ResponseWriter, r *http.Request) {
// Defer a function to recover from any panics.
// When recovering from a panic, log the error condition to
// the App Engine dashboard and send the default image to the user.
defer func() {
if err := recover(); err != nil {
c := appengine.NewContext(r)
c.Errorf("%s", err)
c.Errorf("%s", "Traceback: %s", r.RawURL)
if defaultImage != nil {
w.Header().Set("Content-type", "image/jpeg")
jpeg.Encode(w, defaultImage, &imageQuality)
}
}
}()
// Load images from disk on the first request.
loadOnce.Do(load)
// Make a copy of the background to draw into.
bgRect := backgroundImage.Bounds()
m := image.NewRGBA(bgRect.Dx(), bgRect.Dy())
draw.Draw(m, m.Bounds(), backgroundImage, image.ZP, draw.Over)
// Process each character of the request string.
code := strings.ToLower(r.URL.Path[len(prefix):])
for i, p := range code {
// Decode hex character p in place.
if p < 'a' {
// it's a digit
p = p - '0'
} else {
// it's a letter
p = p - 'a' + 10
}
t := urlMap[i] // element type by index
em := elements[t] // element images by type
if p >= len(em) {
panic(fmt.Sprintf("element index out of range %s: "+
"%d >= %d", t, p, len(em)))
}
// Draw the element to m,
// using the layoutMap to specify its position.
draw.Draw(m, layoutMap[t], em[p], image.ZP, draw.Over)
}
// Encode JPEG image and write it as the response.
w.Header().Set("Content-type", "image/jpeg")
w.Header().Set("Cache-control", "public, max-age=259200")
jpeg.Encode(w, m, &imageQuality)
} For brevity, I've omitted several helper functions from these code listings. See the source code for the full scoop.
Performance

This chart - taken directly from the App Engine dashboard - shows average request latency during launch. As you can see, even under load it never exceeds 60 ms, with a median latency of 32 milliseconds. This is wicked fast, considering that our request handler is doing image manipulation and encoding on the fly.
Conclusions
I found Go's syntax to be intuitive, simple and clean. I have worked a lot with interpreted languages in the past, and although Go is instead a statically typed and compiled language, writing this app felt more like working with a dynamic, interpreted language.
The development server provided with the SDK quickly recompiles the program after any change, so I could iterate as fast as I would with an interpreted language. It's dead simple, too - it took less than a minute to set up my development environment.
Go's great documentation also helped me put this together fast. The docs are generated from the source code, so each function's documentation links directly to the associated source code. This not only allows the developer to understand very quickly what a particular function does but also encourages the developer to dig into the package implementation, making it easier to learn good style and conventions.
In writing this application I used just three resources: App Engine's Hello World Go example, the Go packages documentation, and a blog post showcasing the Draw package. Thanks to the rapid iteration made possible by the development server and the language itself, I was able to pick up the language and build a super fast, production ready, doodle generator in less than 24 hours.
Download the full app source code (including images) at the Google Code project.
Special thanks go to Guillermo Real and Ryan Germick who designed the doodle.








(I don't have comments on this blog, but you can comment on my Google+ post.)
Ben Laurie and I have been working on a longer term plan for improving the foundations of the certificate infrastructure on which most Internet transport security is based on these days. Although Chrome has public key pinning for some domains, which limits the set of permitted certificates, we don't see public key pinning as a long term solution (and nor was it ever designed to be).
For the 10 second summary of the plan, I'll quote Ben: “certificates are registered in a public audit log. Servers present proofs that their certificate is registered, along with the certificate itself. Clients check these proofs and domain owners monitor the logs.”. I would add only that anyone can check the logs: the certificate infrastructure would be fully transparent.
We now have an outline of the basic idea and will be continuing to flesh it out in the coming months, hopefully in conjunction with other browser vendors.
But I thought that, at the outset, it would be helpful to describe some of the limitations to the design space, as I see them:
As I've previously described, side-channels occur when a browser needs to contact a server other than the immediate destination in order to verify a certificate. Revocation checking with OCSP is an example of a side-channel used today.
But in order to be effective, side-channels invariably need to block the certificate verification until they complete, and that's a big problem. The Internet isn't fully connected. Captive portals, proxies and firewalls all mean that the only thing you can really depend on talking to is the immediate destination server. Because of this, browsers have never been able to make OCSP lookups blocking, and therefore OCSP is basically useless for security.
And that's not to mention the privacy, performance and functionality issues that arise from needing side-channels. (What happens when the side-channel server goes down?)
So our design requires that the servers send us the information that we require. We can use side-channels to check up on the logs, but it's an asynchronous lookup.
SSL Stripping is a very easy and very effective attack. HSTS prevents it and is as easy to deploy as anything can be for HTTPS sites. But, despite all this, and despite a significant amount of evangelism, take up has been very limited, even by sites which are HTTPS only and the subject of attacks.
While HSTS really has to be opt-in, a solution to the certificate problem doesn't. Although our scheme is incrementally deployable, the eventual aim is that it's required for everybody. Thankfully, since certificates have to be renewed there's an obvious means to incrementally deploy it: require it for certificates issued after a certain date. Although an eventual hard requirement is still needed, it's a lot less of a problem.
Since the aim is to make it a requirement for all servers, we've sacrificed a lot in order to make it very easy on the server operator. For most server operators, their CA will probably take care of fetching the audit proofs, meaning there's no additional work at all.
Some initial designs included short-lived log signatures, which would have solved the revocation problem. (Revocation would simply be a matter of instructing the logs to stop signing a given certificate.) However, this would have required server operators to update their audit proofs on a near-daily basis. After discussions it became clear that such a requirement wouldn't be tenable for many and so we reluctantly dropped it.
We are also sacrificing decentralisation to make things easy on the server. As I've previously argued, decentralisation isn't all it's cracked up to be in most cases because 99.99% of people will never change any default settings, so we haven't given up much. Our design does imply a central set of trusted logs which is universally agreed. This saves the server from possibly having to fetch additional audit proofs at runtime, something which requires server code changes and possible network changes.
Cheap virtual hosting and EC2 have made multi-homed services common. Even small to medium scale sites have multiple servers these days. So any scheme that asserts that the currently serving certificate is the only valid certificate will run into problems when certificates change. Unless all the servers are updated at exactly the same time, then users will see errors during the switch. These schemes also make testing a certificate with a small number of users impossible.
In the end, the only real authority on whether a certificate is valid is the site itself. So we don't rely on external observations to decide on whether a certificate is valid, instead to seek to make the set of valid certificates for a site public knowledge (which it currently isn't), so that the site can determine whether it's correct.
We believe that this design will have a significant, positive impact on an important part of Internet security and that it's deployable. We also believe that any design that shares those two properties ends up looking a lot like it. (It's no coincidence that we share several ideas with the EFF's Sovereign Keys.)
None the less, deployment won't be easy and, hopefully, we won't be pushing it alone.
As announced on the Google Security Blog, Google HTTPS sites now support forward secrecy. What this means in practice is two things:
Firstly, the preferred cipher suite for most Google HTTPS servers is ECDHE-RSA-RC4-SHA. If you have a client that supports it, you'll be using that ciphersuite. Chrome and Firefox, at least, support it.
Previously we were using RSA-RC4-SHA, which means that the client (i.e. browser) picks a random key for the session, encrypts it with the server's public key and sends it to the server. Since only the holder of the private key can decrypt the session key, the connection is secure.
However, if an attacker obtains the private key in the future then they can decrypt recorded traffic. The encrypted session key can be decrypted just as well in ten years time as it can be decrypted today and, in ten years time, the attacker has much more computing power to break the server's public key. If an attacker obtains the private key, they can decrypt everything encrypted to it, which could be many months of traffic.
ECDHE-RSA-RC4-SHA means elliptic curve, ephemeral Diffie-Hellman, signed by an RSA key. You can see a previous post about elliptic curves for an introduction, but the use of elliptic curves is an implementation detail.
Ephemeral Diffie-Hellman means that the server generates a new Diffie-Hellman public key for each session and signs the public key. The client also generates a public key and, thanks to the magic of Diffie-Hellman they both generate a mutual key that no eavesdropper can know.
The important part here is that there's a different public key for each session. If the attacker breaks a single public key then they can decrypt only a single session. Also, the elliptic curve that we're using (P-256) is estimated to be as strong as a 3248-bit RSA key (by ECRYPT II), so it's unlikely that the attacker will ever be able to break a single instance of it without a large, quantum computer.
While working on this, Bodo Möller, Emilia Kasper and I wrote fast, constant-time implementations of P-224, P-256 and P-521 for OpenSSL. This work has been open-sourced and submitted upstream to OpenSSL. We also fixed several bugs in OpenSSL's ECDHE handling during deployment and those bug fixes are in OpenSSL 1.0.0e.
The second part of forward secrecy is dealing with TLS session tickets.
Session tickets allow a client to resume a previous session without requiring that the server maintain any state. When a new session is established the server encrypts the state of the session and sends it back to the client, in a session ticket. Later, the client can echo that encrypted session ticket back to the server to resume the session.
Since the session ticket contains the state of the session, and thus keys that can decrypt the session, it too must be protected by ephemeral keys. But, in order for session resumption to be effective, the keys protecting the session ticket have to be kept around for a certain amount of time: the idea of session resumption is that you can resume the session in the future, and you can't do that if the server can't decrypt the ticket!
So the ephemeral, session ticket keys have to be distributed to all the frontend machines, without being written to any kind of persistent storage, and frequently rotated.
We believe that forward secrecy provides a fairly significant benefit to our users and we've contributed our work back to OpenSSL in the hope that others will make use of it.
I won’t bore you with the details here; read the PDF for those. Here are some examples to whet your appetite.
A somewhat comprehensive example:
// Package gen provides some example generic functionality.
package gen
// Generic types for this package
type Value generic
type Result generic
type ReduceFunc func(Result, Value) Result
// Tern is the ternary operator: Tern(cond,t,f) == (cond?t:f)
func Tern(cond bool, t, f Value) Value {
if cond {
return t
}
return f
}
// Reduce returns the result of running the ReduceFunc on each successive value
// in list along with the last result.
func (red ReduceFunc) Reduce(r0 Result, list ...Value) Result {
for _, v := range list {
r0 = red(r0, v)
}
return r0
}
// Check strips out the os.Error return from a function call for use inline.
func Check(val Value, err os.Error) Value {
if err != nil {
panic(err)
}
return val
}
Using that package:
package main
import (
"fmt"
"gen"
"strconv"
)
func main() {
add := gen.ReduceFunc(func(x0 int, x1 string) int {
return x0 + gen.Check(strconv.Atoi(x1))
})
nums := os.Args[1:]
fmt.Printf("Sum of your %s: %v\n",
"number" + gen.Tern(len(nums)==1, "", "s"),
add.Reduce(0, os.Args))
}
Everybody’s favorite generic interface:
type Value generic
type Equaler interface {
Equals(other Value) bool
}
// Integer implements Equaler.
type Integer int
func (i Integer) Equals(j Integer) bool {
return i == j
}
// Compile-time check.
var _ Equaler = Integer(0)
// Search returns the index of the first element for which list[idx].Equal(val)
// returns true.
func Search(list []Equaler, val Value) int {
for i, v := range list {
if v.Equal(val) {
return i
}
}
return -1
}
The proposal’s source can be found on github.
The Go Authors went on to produce lots of libraries, new tools, and reams of documentation. They celebrated a successful year in the public eye with a blog post last November that concluded "Go is certainly ready for production use, but there is still room for improvement. Our focus for the immediate future is making Go programs faster and more efficient in the context of high performance systems."
Today is the second anniversary of Go's release, and Go is faster and more stable than ever. Careful tuning of Go's code generators, concurrency primitives, garbage collector, and core libraries have increased the performance of Go programs, and native support for profiling and debugging makes it easier to detect and remove performance issues in user code. Go is also now easier to learn with A Tour of Go, an interactive tutorial you can take from the comfort of your web browser.
This year we introduced the experimental Go runtime for Google's App Engine platform, and we have been steadily increasing the Go runtime's support for App Engine's APIs. Just this week we released version 1.6.0 of the Go App Engine SDK, which includes support for backends (long-running processes), finer control over datastore indexes, and various other improvements. Today, the Go runtime is near feature parity with - and is a viable alternative to - the Python and Java runtimes. In fact, we now serve golang.org by running a version of godoc on the App Engine service.
While 2010 was a year of discovery and experimentation, 2011 was a year of fine tuning and planning for the future. This year we issued several "release" versions of Go that were more reliable and better supported than weekly snapshots. We also introduced gofix to take the pain out of migrating to newer releases. Furthermore, last month we announced a plan for Go version 1 - a release that will be supported for years to come. Work toward Go 1 is already underway and you can observe our progress by the latest weekly snapshot at weekly.golang.org.
The plan is to launch Go 1 in early 2012. We hope to bring the Go App Engine runtime out of "experimental" status at the same time.
But that's not all. 2011 was an exciting year for the gopher, too. He has manifested himself as a plush toy (a highly prized gift at Google I/O and other Go talks) and in vinyl form (received by every attendee at OSCON and now available at the Google Store).

And, most surprisingly, at Halloween he made an appearance with his gopher girlfriend!

Photograph by Chris Nokleberg.
This post might be about a worker synchronization idiom—whatever an idiom is. I don’t know. Is it a way to solve a common problem in a particular language? I don’t even know if idioms are good or bad.
Anyway, suppose you have a data structure and you want to let multiple workers concurrently read from it and, each doing things slightly differently, compute independent results. The workers all need to see the entire data structure, but that’s okay because the data isn’t changing during this read and compute phase. The results need to be combined and reduced. When all the results are in and reduced, the result is used to update the shared data structure. Then it all needs to be repeated for some number of iterations. Is this common? Are there physical simulations or stochastic algorithms that are like this? I would think so.
I know, it’s not sounding like idiomatic Go. It’s communicating by sharing memory. But still, if it’s a common thing and there’s a way to do it in the language, isn’t that an idiom? (Maybe it’s a bad idiom. Then, I’ve heard people say all idioms are bad. Maybe it’s a good idiom for doing a bad thing…) Sometimes though, you have an existing algorithm and you want to follow it, even if it does communicate by sharing memory.
The important feature of the algorithm seemed to be the checkpoints (or barriers or whatever) that separate the phases.
Initialization | processing | update | processing | update | …
It’s not too hard, and surely, like exercise #69 (it seems to be #70 now) there must be lots of ways to do it. Before showing my complete program though, I tried reducing it to a minimal program that would show the just synchronization without the clutter of everything else. It was at that point that the problem struck me as analogous to a horse race.
Initialization is like getting the track groomed and everything all set up. It has to happen without the horses running around. There is just one track. It is shared. To keep the horses from starting, there is a gate that holds them. They all wait at the gate until the gate opens and lets them run. Then they all begin to run concurrently. They finish at different times and some data is recorded. At some point, the gates must close in preparation for the next race.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var horses = []string{"pie", "biscuit", "lap", "derpy"}
const nRaces = 4
var startSignal, gates sync.WaitGroup
var finish = make(chan string, len(horses))
func main() {
startSignal.Add(1)
for _, name := range horses {
go horse(name)
}
places := make([]string, len(horses))
for r := 1; r <= nRaces; r++ {
gates.Add(len(horses))
startSignal.Done()
gates.Wait()
startSignal.Add(1)
for i := range horses {
places[i] = <-finish
}
fmt.Println("race", r, places)
}
}
func horse(horseName string) {
rnd := rand.New(rand.NewSource(time.Nanoseconds()))
for {
// wait for start signal
startSignal.Wait()
gates.Done()
// do something
time.Sleep(9e7+rnd.Int63n(2e7))
// return result
finish <- horseName
}
}
Example output:
race 1 [lap derpy biscuit pie] race 2 [derpy pie biscuit lap] race 3 [biscuit derpy lap pie] race 4 [biscuit derpy pie lap]
It seems a little clunky and mousetrap-like, but I think that might just be the nature of communicating by sharing memory. Results are gathered with a channel in the usual way, and then I use two WaitGroups to implement the latch mechanism of the starting gate. startSignal is binary and is a 1 to N broadcast. All of the horses wait on it to fall to zero, implementing the starting gates opening. Then there is the problem of setting it back to 1 for the start of the next race. It needs to be done before the first horse finishes, or else the horse will find the gate open and begin to run again. It cannot be done immediately on the next line of code however, because that leads to the gate snapping shut before some of the horses have had a chance to leave. The solution was a a separate WaitGroup, this one used in the more common N to 1 mode indicating when each goroutine has completed the step of the horse leaving the gate.
Finally now, the fun program. It’s still just a toy problem, but I coded up an ant colony solution” of the knight’s tour problem as described by Philip Hingston and Graham Kendall. It was fun to reproduce their results and get the same number for cumulative production rate. (Although I couldn’t figure out what they were doing to get the .09 number for mean production rate.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
const boardSize = 8
const nSquares = boardSize * boardSize
const completeTour = nSquares - 1
const cycles = 27000
// pheromone representation read by ants
var tNet = make([]float64, nSquares*8)
// row, col deltas of legal moves
var drc = [][]int{{1, 2}, {2, 1}, {2, -1}, {1, -2},
{-1, -2}, {-2, -1}, {-2, 1}, {-1, 2}}
// get square reached by following edge k from square (r, c)
func dest(r, c, k int) (int, int, bool) {
r += drc[k][0]
c += drc[k][1]
return r, c, r >= 0 && r < boardSize && c >= 0 && c < boardSize
}
// struct represents a pheromone amount associated with a move
type rckt struct {
r, c, k int
t float64
}
func main() {
// waitGroups for ant release clockwork
var start, reset sync.WaitGroup
start.Add(1)
// channel for ants to return tours with pheromone updates
tch := make(chan []rckt)
// create an ant for each square
for r := 0; r < boardSize; r++ {
for c := 0; c < boardSize; c++ {
go ant(r, c, &start, &reset, tch)
}
}
// accumulator for new pheromone amounts
tNew := make([]float64, nSquares*8)
// map for collecting set of complete tours
allUnique := make(map[string]int)
tbuf := make([]byte, 2+completeTour) // for building map key
// heading
fmt.Println("Board size:", boardSize)
fmt.Println("Cycles per repeat:", cycles)
fmt.Println(" Unique Production Cumm.")
fmt.Println(" complete Cumm. Total rate prod.")
fmt.Println("Repeat tours unique attempts this repeat rate")
// each iteration is a "repeat" as described in the paper
for repeat := 1; ; repeat++ {
unique := make(map[string]int) // complete tours this repeat
// initialize board
for r := 0; r < boardSize; r++ {
for c := 0; c < boardSize; c++ {
for k := 0; k < 8; k++ {
if _, _, ok := dest(r, c, k); ok {
tNet[(r*boardSize+c)*8+k] = 1e-6
}
}
}
}
// each iteration is a "cycle" as described in the paper
for i := 0; i < cycles; i++ {
// evaporate pheromones
for i := range tNet {
tNet[i] *= .75
}
reset.Add(nSquares) // number of ants to release
start.Done() // release them
reset.Wait() // wait for them to begin searching
start.Add(1) // reset start signal for next cycle
// gather tours from ants
for i := 0; i < nSquares; i++ {
tour := <-tch
// accumulate complete tours
if len(tour) == completeTour {
tbuf[0] = byte(tour[0].r)
tbuf[1] = byte(tour[0].c)
for i, m := range tour {
tbuf[i+2] = byte(m.k)
}
key := string(tbuf)
unique[key] = 1
allUnique[key] = 1
}
// accumulate pheromone amounts from all ants
for _, move := range tour {
tNew[(move.r*boardSize+move.c)*8+move.k] += move.t
}
}
// update pheromone amounts on network, reset accumulator
for i, tn := range tNew {
tNet[i] += tn
tNew[i] = 0
}
}
// print statistics
// fmt.Println(" Unique Production Cumm.")
// fmt.Println(" complete Cumm. Total rate prod.")
// fmt.Println("Repeat tours unique attempts this repeat rate")
fmt.Printf("%6d %9d %9d %10d %6.4f %6.4f\n",
repeat, len(unique), len(allUnique), repeat*cycles*nSquares,
float64(len(unique))/float64(cycles*nSquares),
float64(len(allUnique))/float64(repeat*cycles*nSquares))
}
}
func printTour(tour []rckt) {
seq := make([]int, nSquares)
for i, sq := range tour {
seq[sq.r*boardSize+sq.c] = i + 1
}
last := tour[len(tour)-1]
r, c, _ := dest(last.r, last.c, last.k)
seq[r*boardSize+c] = nSquares
fmt.Println("Move sequence:")
for r := 0; r < boardSize; r++ {
for c := 0; c < boardSize; c++ {
m := seq[r*boardSize+c]
if m > 0 {
fmt.Printf(" %3d", seq[r*boardSize+c])
} else {
fmt.Print(" ")
}
}
fmt.Println()
}
}
type square struct {
r, c int
}
func ant(r, c int, start, reset *sync.WaitGroup, tourCh chan []rckt) {
rnd := rand.New(rand.NewSource(time.Nanoseconds()))
tabu := make([]square, nSquares)
moves := make([]rckt, nSquares)
unexp := make([]rckt, 8)
tabu[0].r = r
tabu[0].c = c
for {
// cycle initialization
moves = moves[:0]
tabu = tabu[:1]
r := tabu[0].r
c := tabu[0].c
// wait for start signal
start.Wait()
reset.Done()
for {
// choose next move
unexp = unexp[:0]
var tSum float64
findU:
for k := 0; k < 8; k++ {
dr, dc, ok := dest(r, c, k)
if !ok {
continue
}
for _, t := range tabu {
if t.r == dr && t.c == dc {
continue findU
}
}
tk := tNet[(r*boardSize+c)*8+k]
tSum += tk
// note: dest r, c stored here
unexp = append(unexp, rckt{dr, dc, k, tk})
}
if len(unexp) == 0 {
break // no moves
}
rn := rnd.Float64() * tSum
var move rckt
for _, move = range unexp {
if rn <= move.t {
break
}
rn -= move.t
}
// move to new square
move.r, r = r, move.r
move.c, c = c, move.c
tabu = append(tabu, square{r, c})
moves = append(moves, move)
}
// compute pheromone amount to leave
for i := range moves {
moves[i].t = float64(len(moves)-i) / float64(completeTour-i)
}
// return tour found for this cycle
tourCh <- moves
}
}
Output:
Board size: 8
Cycles per repeat: 27000
Unique Production Cumm.
complete Cumm. Total rate prod.
Repeat tours unique attempts this repeat rate
1 176027 176027 1728000 0.1019 0.1019
2 172491 348518 3456000 0.0998 0.1008
3 201836 550354 5184000 0.1168 0.1062
4 104574 654928 6912000 0.0605 0.0948
5 117130 772058 8640000 0.0678 0.0894
...
95 193387 12424890 164160000 0.1119 0.0757
96 37647 12462537 165888000 0.0218 0.0751
97 121887 12584424 167616000 0.0705 0.0751
98 145072 12729496 169344000 0.0840 0.0752
99 162658 12892154 171072000 0.0941 0.0754
100 206599 13098753 172800000 0.1196 0.0758







There is no chance that Edward de Vere, the Earl of Oxford, wrote the plays attributed to William Shakespeare.
That said, I found the movie Anonymous to be reasonably watchable, although I thought many of Vanessa Redgrave’s scenes as the older Queen Elizabeth were ridiculous. But since the movie claims (perhaps as a joke) to be seriously advocating the position that Oxford wrote the plays, I was surprised that they did such a poor job of supporting the theory.
Oxford was shown as being tutored at length on topics other than poetry. He traveled abroad, he intrigued at court. When would he have had time to write the plays and the sonnets? The movie essentially presents Oxford as being mysterious gifted by the ability to write; he speaks of continual voices in his head. That could happen to anybody, and perhaps describes the real Shakespeare–if anybody could have written Shakespeare’s plays, then why not Shakespeare himself?
Oxford is shown as using the plays to support his court intrigues. Is it possible to imagine Shakespeare, with his clear vision of humanity, thinking that he could achieve such ends through his plays? One of the strongest examples of that in the movie was the suggestion that it was odd that Shakespeare portrayed Richard III as a hunchback, but even I know that Richard III was popularly (and probably falsely) considered to be a hunchback long before Shakespeare’s time.
Of course it’s conceivable if unlikely that somebody else wrote Shakepeare’s plays. But the undercurrent of the Oxford theory has always been that a member of the nobility would be more likely as the playwright than a commoner. But this reverses reality. The nobility were highly trained from birth in their roles in society. They were busy people with lots to do. It was far less likely that an earl could write the plays than a member of the middle class. As far as I know only one member of the English nobility ever achieved any note as an author: Lord Dunsany, who lived much later.
The movie did have a couple of nice (non-Shakespearean) lines, one of which, by the Ben Jonson character, was simply the truth: the only reason future ages remember the people who lived then was because they were alive when Shakespeare was writing.
One of the key benefits of the Go runtime, apart from working in a fantastic language, is that it has high performance. Go applications compile to native code, with no interpreter or virtual machine getting between your program and the machine.
Making your web application fast is important because it is well known that a web site's latency has a measurable impact on user happiness, and Google web search uses it as a ranking factor. Also announced in May was that App Engine would be leaving its Preview status and transitioning to a new pricing model, providing another reason to write efficient App Engine applications.
To make it easier for Go developers using App Engine to write highly efficient, scalable applications, we recently updated some existing App Engine articles to include snippets of Go source code and to link to relevant Go documentation.
By David Symonds, November 2011Among the improvements are the ability to inspect goroutines and to print native Go data types, including structs, slices, strings, maps, interfaces, and channels.
To learn more about Go and GDB, see the Debugging with GDB article.
After writing my last post, I again worked my arse off this week to study both the Stanford AI and ML classes in a less crunchy fashion than the week before. Unfortunately the crunch avoidance did not come to pass and I was up until 3am this morning (well, 2am if you take into account the clocks going back :-) cramming on AI.
Since I actually want to learn about AI (and apply it to weak) I am not finding this cramming aspect of the study particularly beneficial. In my experience, cramming simply wears you out and gets you ready for a given short-term task (e.g. homework, later exams) before the information you’ve learned largely plops out of your brain.
For that reason, and for the sake of keeping this doable, I’ve decided to drop the machine learning course and focus fully on AI. There is an irony in that - I have found the AI work to be considerably more involved and challenging than machine learning (that’s not a comment on the relative quality of one course vs. the other by the way), however a. AI is of more relevance to what I want to do, and b. focusing on one thing reduces the stressful feeling of distraction that maintaing another course which requires homework, etc. brings.
I am still very interested in machine learning, so I might very well go over the machine learning course material at a later date. Additionally, the AI course contains some cross-over material so I won’t do entirely without.
Another aspect is that I would like to maintain my notes to a better standard than I have (and which more time would allow me to achieve), rather than having to rush them out because of time constraints. There are almost certainly better notes for the course out there, however there is nothing quite like having a set of notes to refer to you which you’ve written in your own style and to your own tastes. Not invented here syndrome, perhaps!
On an entirely different subject, you may have noticed I’ve deleted a number of posts. This is because I felt they were of little value and often quite negative. This blog is meant to be a diary of where I’m at in my tech life, and yes that involves both positive and negative, however there is nothing more tedious than wading through either rather mediocre technical posts, or moany personal ones. I’d like to maximise the chances of me (and to some degree others of course :-) actually enjoying reading this blog.
I can only apologise to those few whose comments have consequently been deleted from this site. Hopefully you can understand why I’ve done it.
The lure of Sprint was too strong to pass up, but ultimately ended in letdown and abandon.
Sprint's pitch was simple. Where else can you get an all you can eat data plan and ample minutes for $75.00 including the government’s taxation scheme that Karl Marx would be proud of? Done. Sign me up.
Choosing a phone for Sprint's network was not as easy. They offer three compelling choices.
First, you can speak random thoughts of consciousness in a Sprint store, and if a customer has pressed the Siri button on the display model iPhone 4s, you'll likely get verbal confirmation to choose it.
For those flirting with escape from Jobs’ utopia, the gorilla glass encased false god of Android is eager to entice, with a Samsung Galaxy S II. Like a hollywood celeb it's light weight and beautiful.
But for some, age brings truth, hence the third option, a year old Samsung Nexus S anointed with the purity of plain Gingerbread. I chose this option.
Despite the sweetness of Gingerbread, there is nothing tasty about Samsung’s Nexus S. Extremely poor antennas for wifi, 3g and 4g? Check. A battery that can’t last ½ day with light to moderate use? Check. Screen jitter while scrolling through your twitter feed? Check.
Needless to say the phone went back to the Sprint store. This left two choices left. The iPhone 4s and the Galaxy S II. I opted with the Galaxy S II.
The Galaxy S II represents everything that is right and wrong about Android, the device manufacturers, and the carriers.
On the Galaxy S II, gone is the jerky scrolling of the Nexus S. The screen is vibrant and huge. Samsung retained its use of a plastic enclosure, yet improved its sturdiness, a move that makes the device feel better quality. The antennas are dramatically better, resulting in greater wifi availability and improved call quality.
Unfortunately, the battery still sucks. And Samsung managed to load the device up with crap ware that you cannot delete from the application menu.
To mitigate the battery life, I bought a few chargers to plant at strategic locations at home, in the car and at the office. And most of the crap ware can be stashed in a folder on the desktop. This uncluttered things enough to pass inspection.
Just as I was getting used to the device, and on the last day of my free trial, Sprint dropped the mother of all bombs. They announced the ending of the unlimited data plan. Furthermore, current users would not be grandfathered in, and thus would be subject to huge data overage charges.
This triggered my immediate cancellation of the Sprint plan.
The data plan was the only reason why I went to Sprint in the first place. With Sprint customers faced a trade-off. You received unlimited data for a unreliable network that has poor coverage in rural areas.
With their latest decision, there is no tradeoff, and therefore no logical reason why anyone whould choose Sprint over another network.
I leveraged the "winback" program AT&T offers customers who made the transgression of choosing another carrier. They put you back on the program exactly as you left it at no charge.
So here I am, back with AT&T using a feature phone with nothing but time to ponder my next move.
Do I wait three weeks for Samsung’s Galaxy Nexus that boasts Ice Cream Sandwich, Google’s new OS? Do l let lust get the best of me, and choose a Windows Phone 7, with the Mango update, knowing I'll likely be ultiamtely dissapointed with its feature incompleteness? Or do I return to utopia with an iPhone 4s?
The reality is that in this temporal existence, utopia doesn’t exist and there is no perfect phone. Therefore, I’m sticking with my wife’s old feature phone.
Am currently attempting to do both the Stanford AI and Machine Learning courses at once. My brain is melting.
I’m keeping my ongoing rough notes on github, I’m writing them in markdown so they render relatively nicely there.
I have realised that, if I am actually going to see both courses through to the end, I am going to have to put everything else on hold until they’re done.
Luckily, they both pertain to greater or lesser degrees to weak so its not entirely a pause on other projects. Also, I might choose to hack on weak from time-to-time since I am chomping at the bit to get it moving.
{kind=link}